Learning to Learn: A LATS-Based Framework for Self-Aware AI Pipelines

📖 Summary
In this post, we introduce the LATSAgent, an implementation of LATS: Language Agent Tree Search Unifies Reasoning.. within the stephanie framework. Unlike prior agents that followed a single reasoning chain, this agent explores multiple reasoning paths in parallel, evaluates them using multidimensional scoring, and learns symbolic refinements over time. This is our most complete integration yet of search, simulation, scoring, and symbolic tuning bringing together all of our previous work on sharpening, pipeline reflection, and symbolic rules into a unified, intelligent reasoning loop.
This work integrates LATS a powerful reasoning search strategy into a larger self-improving AI pipeline. Our goal is not just better outputs, but better learning: a system that reflects, adapts, and improves over time.
🎯 Why Build This?
Most LLM-based agents today are limited by:
- ❌ Single-path thinking They generate one answer at a time, with no way to explore or compare alternatives.
- ❌ Shallow feedback Binary pass/fail evaluations give no clue why something worked or failed.
- ❌ Rigid prompts They can’t adapt or learn from past mistakes without retraining.
We built LATS to fix these limitations. It’s a reasoning engine that:
- 🌳 Explores multiple paths using Monte Carlo Tree Search (MCTS)
- 🕸️ Learns from structured feedback with dimensional scoring
- 🔁 Improves itself by tuning symbolic reasoning rules on the fly
Together with CoR-style scoring and DSPy-inspired rule refinement, LATS becomes more than just an agent it becomes a self-aware system that learns how to think better over time.
🎲 Why Monte Carlo Tree Search (MCTS)?
MCTS is a powerful algorithm for decision-making under uncertainty. It works by:
- Simulating many possible futures from a given state (exploration).
- Evaluating them based on some scoring heuristic (exploitation).
- Progressively biasing search toward high-reward areas of the space.
In reasoning tasks like chain-of-thought or multi-step question answering, the key challenge is not just generating one output it’s exploring different possible reasoning paths and selecting the best.
We chose MCTS because it:
- Balances exploration and exploitation: It doesn’t just pick the first plausible answer, it tries multiple reasoning paths.
- Builds a structured reasoning tree: This is ideal for debugging, analyzing, or optimizing reasoning later.
- Is interpretable: Each node in the tree contains a state, a trace, and a score so we can trace why a path was chosen.
- Supports incremental improvement: With each run, the system learns which branches perform better, which is crucial for self-improvement loops.
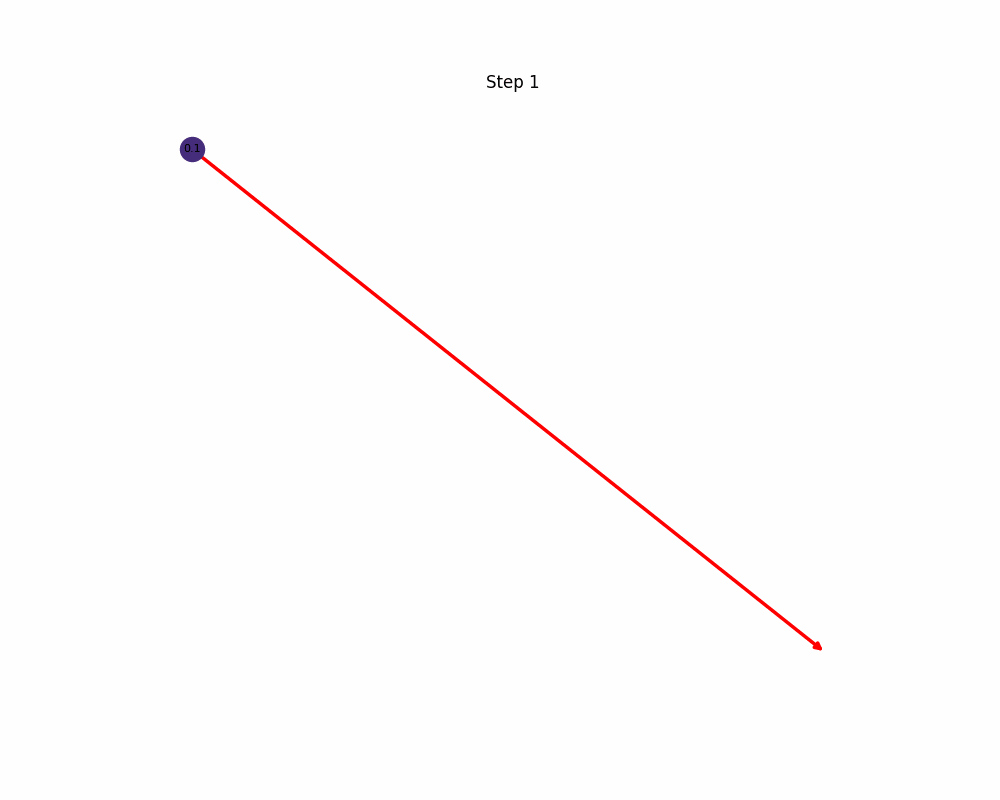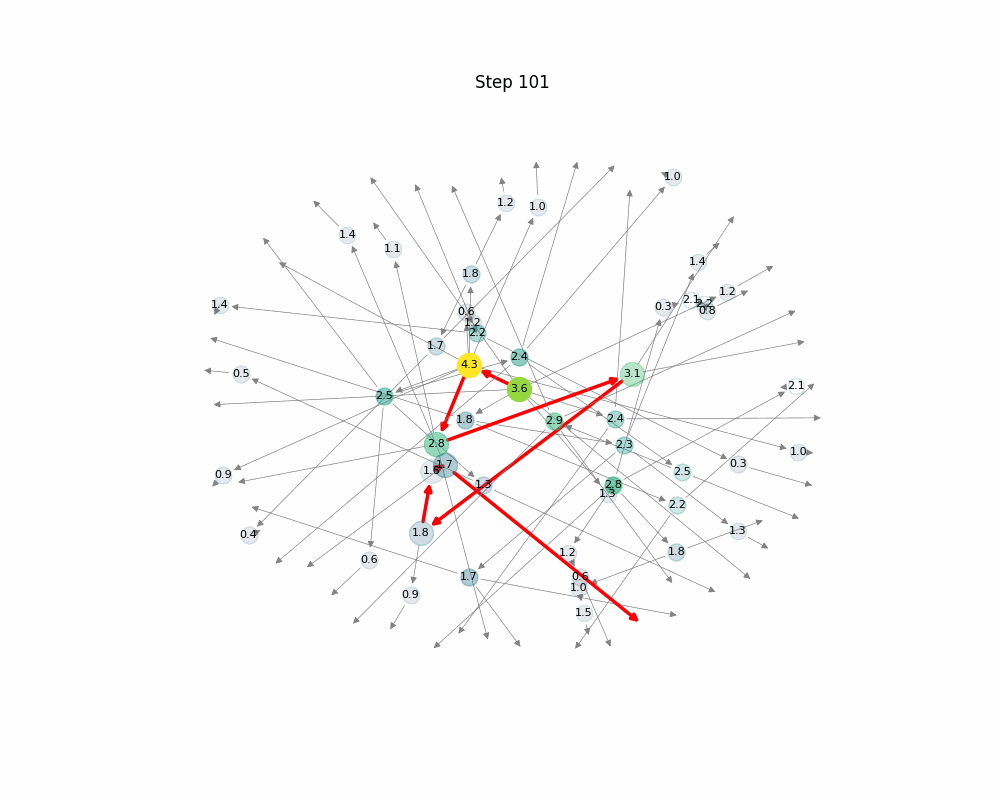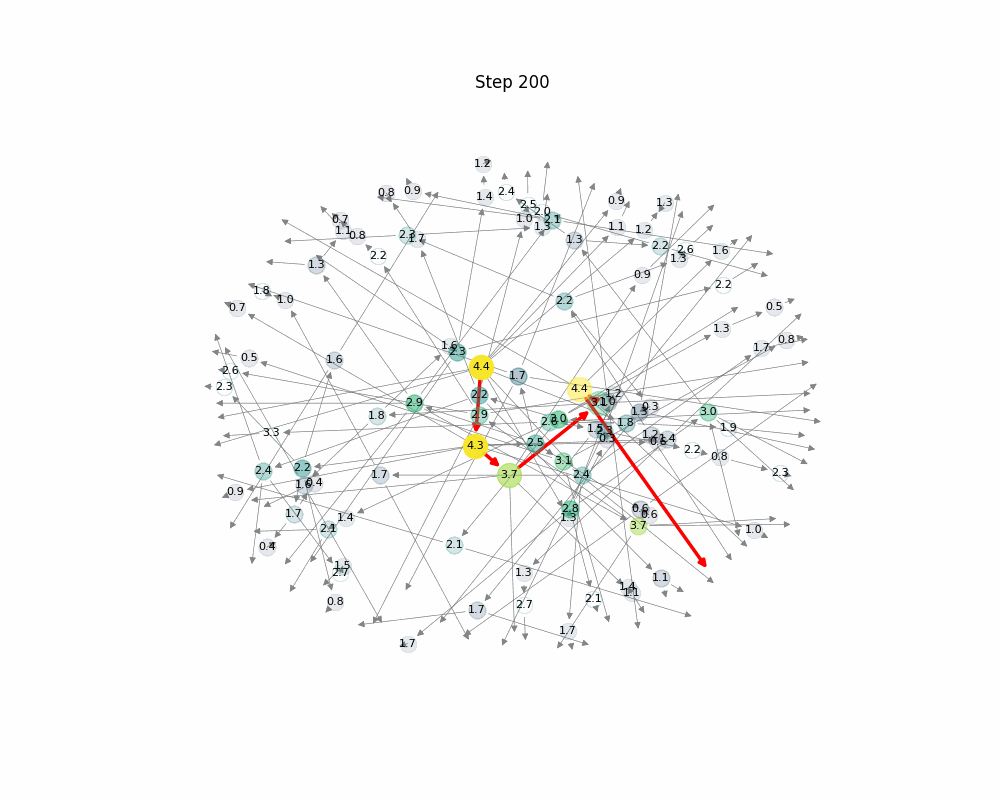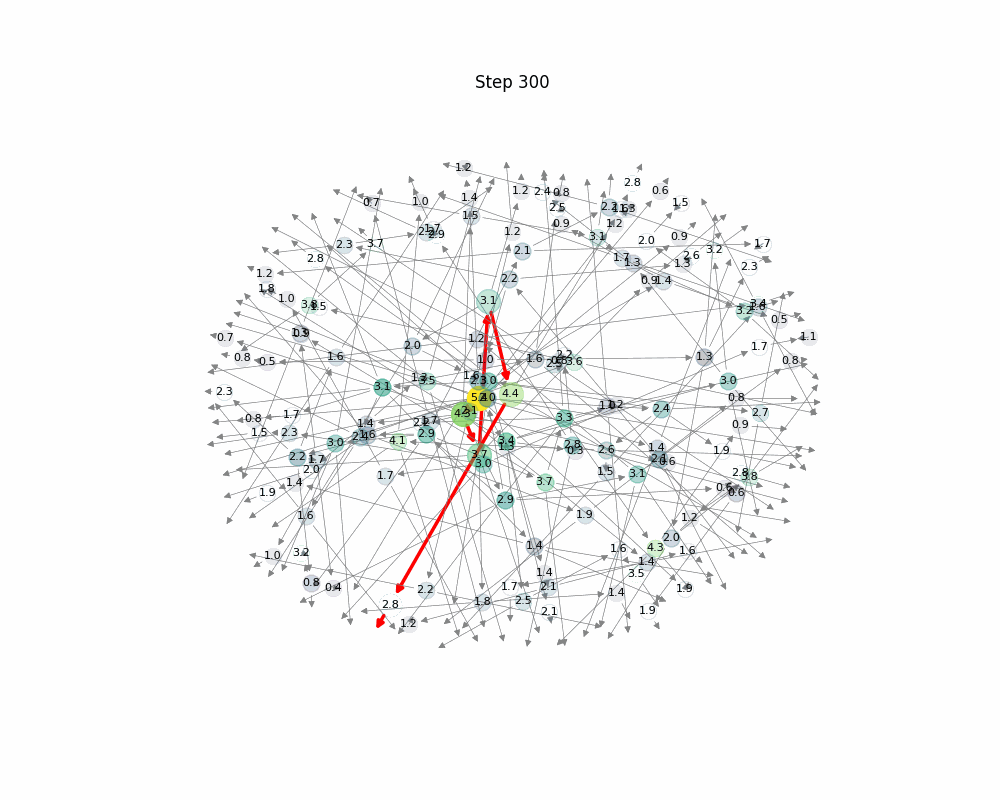
This animated image shows a Monte Carlo Tree Search (MCTS) process in action. Starting from a single root node, the algorithm expands a tree by simulating and evaluating different paths over 300 steps.
- Nodes grow and fade as they are visited or abandoned.
- Colors represent cumulative reward brighter nodes are more promising.
- The red path highlights the best-performing reasoning trajectory so far, based on reward.
- Over time, the tree biases exploration toward more valuable branches, illustrating how MCTS balances exploration and exploitation to refine its search.
We adopt LATS as the reasoning core of our system not to end with a single answer, but to explore the space of thought. In our broader framework, this structured reasoning becomes the substrate for self-refinement.
📚 Why the LATS Paper?
LATS stands for Language Agent Tree Search, a framework introduced by Zhou et al. (2024) that reimagines how language agents can reason, act, and plan in a unified loop. It’s not just another prompting trick it’s a full architecture for intelligent decision-making over time.
🔍 What LATS brings to our system:
- Structured reasoning as tree search: Instead of generating one-off answers, LATS builds and explores a search tree of reasoning paths. This mirrors how humans often think exploring options, backtracking, and refining.
- Tool use and symbolic action: Each node in the tree can invoke tools, retrieve facts, or apply symbolic rules. This makes LATS a perfect match for our hybrid Co AI system, which mixes LLMs with structured knowledge and symbolic operations.
- Self-improving behavior: Every tree traversal is data. Each node captures a decision, an outcome, and a score. This data is critical for bootstrapping better prompts, strategies, or even training smaller models (e.g., via MR.Q).
- Compatible with DSPy and module-level optimization: The original paper introduces Bootstrapped Few-Shot Learning and modular DSPy-style training. This fits perfectly with our goal of learning prompts and strategies from examples.
🎯 Why We’re Implementing It
We’re starting with the DSPy-style hypothesis generation use case, where the LATS agent simulates reasoning paths and evaluates each using a scoring model (e.g., MR.Q or LLM judge). This gives us a diverse set of reasoning chains, not just a single output, and helps surface more insightful or original hypotheses.
But that’s just the beginning.
🧭 Our long-term vision is to extend LATS into pipeline optimization not just reasoning within a step, but choosing and refining the steps themselves.
By collecting traces and scores at every stage, we can learn which symbolic rules, tools, or strategies work best and use MCTS to actively select and improve entire pipelines.
By evolving our LATS implementation from generating diverse reasoning paths within individual hypothesis generation tasks toward optimizing entire reasoning pipelines, we rely heavily on symbolic foundations established earlier. Our previous exploration of symbolic rules and structured feedback mechanisms laid crucial groundwork, allowing us to represent, analyze, and refine reasoning systematically. Now, we’re translating those symbolic insights into active components of our reasoning process transforming static symbolic representations into dynamic tools for continuous self-improvement and optimization.
flowchart LR
A[🎯 Goal] --> B[🌳 LATS Reasoning Process]
B --> C[💡 Multi-Path Exploration]
B --> D[📏 Dimensional Scoring]
D --> E[📊 Output Evaluation]
C --> E
E --> F[🔁 Feedback & Learning]
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333,stroke-width:2px
style C fill:#ddf,stroke:#333,stroke-width:1px
style D fill:#ffd,stroke:#333,stroke-width:1px
style E fill:#cfc,stroke:#333,stroke-width:1px
style F fill:#fcf,stroke:#333,stroke-width:2px
🚀 Before/After LATS Integration
| Traditional Approach | LATS-Enhanced System |
|---|---|
| Single reasoning path | 72 parallel explored paths |
| Binary right/wrong scoring | 6-dimensional quality analysis |
| Static pipelines | Self-optimizing workflows |
🧠 From Symbols to Self-Improvement: Foundations of Feedback
This work builds directly on our earlier post “Programming Intelligence” , which introduced the core idea of using symbolic representations such as rules, scores, and evaluation dimensions to track and refine AI reasoning.
That post established:
- A structured graph of symbolic rule applications, capturing how decisions evolve.
- A feedback loop powered by dimension-specific scoring (like correctness, clarity, feasibility).
- The insight that symbolic analysis can guide improvement, not just reporting.
In this current work, we elevate that foundation into a dynamic reasoning environment. The symbolic graph is no longer just a record it’s part of a live system:
- Each node in the LATS tree is now scored using these symbolic dimensions.
- Symbolic divergence and convergence between reasoning paths can now trigger reflection.
- We compare graphs from different processes to discover gaps, redundancies, or synergies.
In short: the symbolic post gave us the vocabulary. This system gives us the dialogue.
📏 Scoring in Multiple Dimensions: Understanding Quality Beyond 1s and 0s
Another major pillar of this work comes from “Dimensions of Thought”, where we introduced the idea that AI-generated hypotheses should be evaluated not just as right or wrong, but across rich, interpretable dimensions like:
- ✅ Correctness
- 🔍 Clarity
- 🧩 Completeness
- 🤝 Alignment
- 💡 Insightfulness
- 🧠 Feasibility
This led to a more nuanced evaluation framework and the design of a reusable scoring interface including prompt templates, output parsers, and structured storage that we now reuse directly in the LATS system.
In our current implementation, this scoring engine:
- Evaluates each node in the tree based on its reasoning quality.
- Supports downstream analysis like impact tracing, symbolic rule tuning, and reasoning-path comparison.
- Provides the ground truth signal for symbolic self-improvement across strategies.
Put simply: without dimensional scoring, LATS would know how to generate but not how to improve.
graph TD
A[AI Generated Hypothesis] --> B[Dimensional Scoring Engine]
subgraph Scoring Dimensions
B --> C[✅ Correctness]
B --> D[🔍 Clarity]
B --> E[🧩 Completeness]
B --> F[🤝 Alignment]
B --> G[💡 Insightfulness]
B --> H[🧠 Feasibility]
end
subgraph Downstream Analysis & Improvement
C --> I[Impact Tracing]
D --> J[Symbolic Rule Tuning]
E --> K[Reasoning Path Comparison]
F --> I
G --> J
H --> K
end
I --> L[Symbolic Self-Improvement]
J --> L
K --> L
Now that we’ve established why dimensional scoring matters, let’s examine how it drives pipeline evolution.
🔄 Revisiting Self-Improving Pipelines: A First Step
This project is also an evolution of our earlier exploration in “The Self-Aware Pipeline”, where we proposed that AI systems could monitor and adjust their own behavior by tracking the paths taken through modular agent pipelines.
That earlier post laid the groundwork by:
- Showing that pipelines could be dynamically reconfigured based on feedback.
- Introducing the idea of reflection agents that evaluate performance post-execution.
- Emphasizing the value of path-tracking in agent workflows.
While this current system (LATS + symbolic scoring) builds a new architecture based on tree-based reasoning, dimensional scoring, and symbolic comparison the core ambition remains the same:
Let the AI learn not just from what it says, but from how it thinks.
We now see the original pipeline work as a stepping stone toward a more structured, introspective, and analyzable system.
🪞 Sharpening the Reasoning Process: Learning to Learn
A core influence on this work came from our Self-Improving Agents post, where we introduced the idea that an AI system could refine its own reasoning through structured feedback and preference modeling.
That framework taught us:
- To treat prompts and reasoning steps as programs that can be improved.
- To apply structured, MR.Q-style feedback for learning which outputs were better.
- That feedback should not be just pass/fail but detailed, dimensional, and symbolically traceable.
In fact, parts of the LATS agent reuse logic directly from the Sharpening codebase:
- The CoR scoring format we use for tree evaluation.
- The idea of contrastive analysis between high- and low-performing traces.
- The start of our symbolic scoring loops.
Where Sharpening focused on refining flat outputs, LATS extends the idea to entire trees of reasoning, enabling us to score paths, trace contributions, and generate actionable feedback at every level.
This work is Sharpening but deeper, more structural, and symbolic.
flowchart TD
A[📥 Initial Prompt + Hypothesis] --> B[🧠 MR.Q Evaluation]
B --> C[⚖️ Is hypothesis good enough?]
C -- No --> D[🔁 Apply Sharpening Templates: CRITIC, GROWS, RECAP...]
D --> E[🤖 Generate Sharpened Hypothesis via LLM]
E --> F[📏 Re-evaluate via MR.Q]
F --> C
C -- Yes --> G[✅ Final Sharpened Hypothesis]
G --> H[💾 Store improved prompts & hypotheses]
style A fill:#FFFBCC,stroke:#333,stroke-width:2px
style B fill:#CCE5FF,stroke:#333,stroke-width:2px
style D fill:#E0F8E0,stroke:#333,stroke-width:2px
style E fill:#F8E0E0,stroke:#333,stroke-width:2px
style G fill:#D9CCFF,stroke:#333,stroke-width:2px
style H fill:#CCF8FF,stroke:#333,stroke-width:2px
🧠 Problem: The Limitations of Static Prompting
Traditional LLM-based reasoning systems often fall into two traps:
- Single-path thinking: Greedy decoding or static CoT prompts fail to explore multiple strategies
- Opaque scoring: Binary pass/fail metrics or heuristic scores without actionable feedback
This leads to brittle pipelines where:
- Similar failures repeat across runs
- High-performing patterns aren’t reused
- Score deltas don’t translate to meaningful improvements
🚀 Solution: LATS + Symbolic Evolution
Our system implements the Language Agent Tree Search (LATS) framework with three key enhancements:
- Symbolic Rule Tuning
- Graph-Based Proximity Matching
- Dimension-Aware Reward Modeling
🧪 Core Architecture Overview
graph TD
A[LATS Agent] --> B[Core Components]
B --> B1[BaseMCTSAgent]
B --> B2[ScoringMixin]
B --> B3[BaseAgent]
A --> C[Workflow]
C --> C1[Root Node Initialization]
C1 --> C2[Monte Carlo Tree Search]
C2 --> D[Selection using UCT]
D --> E{Is Terminal?}
E -- No --> F[Expansion]
E -- Yes --> G[Simulation]
F --> G
G --> H[Backpropagation]
H --> I[Log Progress]
I --> J[Periodic Refinement]
A --> K[Symbolic Integration]
K --> L[ProximityAgent]
K --> M[RuleTunerAgent]
K --> N[UnifiedMRQAgent]
K --> O[SymbolicImpactAnalyzer]
A --> P[Final Output]
P --> Q[Best Path via UCT]
Q --> R[Mermaid Visualization]
R --> S[Final Hypothesis]
S --> T[Store in Memory]
🛠️ Key Components
1. LATS Agent with Tree Search
class LATSAgent(ScoringMixin, BaseAgent):
def __init__(self, cfg, memory=None, logger=None):
self.max_depth = cfg.get("max_depth", 5)
self.ucb_weight = cfg.get("ucb_weight", 1.41)
self.N = defaultdict(int) # visit count
self.W = defaultdict(float) # total reward
self.children = dict() # node -> children
Key Features:
- MCTS with UCT: Balances exploration/exploitation
- Structured State: Uses dict-based state for rich context
- Safe Trace Handling: Prevents string/list mismatches
2. ProximityAgent for Knowledge Reuse
class ProximityAgent(BaseAgent):
def __init__(self, cfg, memory=None, logger=None):
self.similarity_threshold = cfg.get("similarity_threshold", 0.75)
self.max_graft_candidates = cfg.get("max_graft_candidates", 3)
Why It Matters:
- Prevents redundant exploration
- Enables hypothesis grafting from similar paths
- Tracks structural divergence via
compare_graphs
3. SymbolicImpactAnalyzer
class SymbolicImpactAnalyzer:
def __init__(self, score_lookup_fn):
self.score_lookup_fn = score_lookup_fn
def analyze(self, graph1, graph2):
matches, only_1, only_2 = compare_graphs(graph1, graph2)
results = []
for node in matches:
score_1 = self.score_lookup_fn(node, source="graph1")
score_2 = self.score_lookup_fn(node, source="graph2")
results.append({"node": node, "type": "converged", "delta": score_2 - score_1})
return results
Insight:
Tracks score deltas between paths to identify:
- Converged patterns (successful strategies)
- Diverged paths (failed experiments)
- Structural improvements
🧩 Implementation Highlights
1. Structured State Management
def _update_state(self, state_dict, action):
new_state = state_dict.copy()
new_state["current"] = state_dict["current"] + "\n" + action
new_state["trace"] = state_dict["trace"] + [action]
return new_state
Lesson Learned:
Early attempts used string-based state concatenation, causing errors when accessing node["trace"].
Fix:
Always use dictionary state with "current" (full reasoning path) and "trace" (list of steps)
2. Robust Node Scoring
def score_hypothesis(self, hyp, context, metrics="lats_node"):
scorer = self.get_scorer(metrics)
dimension_scores = scorer.evaluate(
hypothesis=hyp,
context=context,
llm_fn=self.call_llm
)
weighted_total = sum(
s["score"] * s.get("weight", 1.0)
for s in dimension_scores.values()
)
weight_sum = sum(s.get("weight", 1.0) for s in dimension_scores.values())
final_score = round(weighted_total / weight_sum, 2) if weight_sum > 0 else 0.0
return {
"id": hyp.get("id"),
"score": final_score,
"scores": dimension_scores
}
Key Insight:
Dimensional scores (correctness, insightfulness, feasibility) enable targeted improvements.
3. Dimensional Scoring System
The Dimensional Scoring System is a flexible and reusable evaluation framework that scores AI outputs across multiple configurable dimensions such as correctness, feasibility, insightfulness, and more.
Key features:
- ✅ Customizable Dimensions: Add as many dimensions as needed (e.g., correctness, alignment, originality), each with its own weight and scoring parser.
- 🔍 Format-Aware: Supports CoR-style structured scoring, numeric extractors, or simple LLM-based judgments.
- 🔄 Agent-Agnostic: Can be plugged into any agent, at any step in the reasoning pipeline.
- 🧩 Compositional and Extensible: Works seamlessly with symbolic rules, self-improvement loops, and scoring analytics.
By evaluating outputs in a multi-dimensional space, this system gives agents richer feedback and enables self-tuning, comparative analysis, and strategic learning over time.
dimensions:
- name: correctness
file: correctness_cor.txt
weight: 1.2
extra_data:
parser: numeric_cor
- name: feasibility
file: feasibility_cor.txt
weight: 1.1
extra_data:
parser: numeric_cor
- name: insightfulness
file: insightfulness_cor.txt
weight: 1.3
extra_data:
parser: numeric_cor
- name: alignment
file: alignment_cor.txt
weight: 1.0
extra_data:
parser: numeric_cor
- name: completeness
file: completeness_cor.txt
weight: 0.8
extra_data:
parser: numeric_cor
Prompt Template (correctness_cor.txt):
Rubric:
- Does the hypothesis directly address the goal?
- Are all logical steps valid?
<eval>
Evaluate the hypothesis:
Goal: {{ goal.goal_text }}
Hypothesis: {{ hypothesis.text }}
</eval>
<answer>[[85]]</answer>
Why It Works:
Structured prompts force LLM to follow rubrics, enabling:
- Consistent scoring
- Actionable feedback
- Easy parsing for reward modeling
4. UnifiedMRQAgent for Reward Modeling
async def run(self, context: dict) -> dict:
hypotheses = context.get("hypotheses", [])
if not hypotheses:
hypotheses = self.memory.hypotheses.get_all(
pipeline_run_id=context.get(PIPELINE_RUN_ID)
)
# Generate contrast pairs
contrast_pairs = self._generate_contrast_pairs(hypotheses)
# Train reward models
trained_models = self.trainer.train_multidimensional_model(contrast_pairs)
context["unified_mrq_model_paths"] = {
dim: os.path.join(self.output_dir, f"{dim}_mrq.pkl")
for dim in trained_models
}
return context
Training Strategy:
- Contrast pairs from high/low scoring hypotheses
- Dimension-specific models for:
correctnessinsightfulnessfeasibility
🧠 Why DSPy?
DSPy is a modular prompting framework that:
- Treats prompts as programmable modules (not strings)
- Enables compile-time optimization of prompts
- Supports training and refinement of reasoning patterns
- Integrates with LATS’ tree search and reflection
This aligns perfectly with the LATS paper’s emphasis on planning via search algorithms and self-reflection-based improvement.
DSPy contributes to the “learning to learn” by enabling prompts to be refined, effectively teaching the model how to reason better.
🔧 Core DSPy Components
The LATS system uses DSPy Signatures to enforce structure, optimize reasoning quality, and support end-to-end trace refinement. Below are the key modules and why they matter:
1. TraceStep: Step-by-Step Reasoning Core
class TraceStep(dspy.Signature):
"""
Signature for each reasoning step in LATS.
"""
state = InputField()
trace = InputField()
next_step = OutputField()
Key Insights
| Feature | Why It’s Important |
|---|---|
✅ Predict(TraceStep) |
Enforces structured generation |
✅ Loop with max_depth |
Limits recursive reasoning depth |
✅ _update_state() |
Maintains evolving context |
| ✅ Terminal check | Prevents infinite loops |
This is how your agent:
- Generates multiple thoughts/actions per step
- Tracks reasoning path in
trace - Builds full reasoning trees for MCTS
🧠 Why This Matters
- Structured Thinking: Each node in the tree is built from this step encouraging modular, composable reasoning.
- Traceable Logic: The full reasoning chain is logged and scored.
- Training & Optimization: Can be plugged into prompt tuning, MR.Q, or DSPy’s compiler for supervised feedback.
2. ReflectionPrompt: Analyzing Failures
class ReflectionPrompt(Signature):
"""
Self-reflection module to analyze failed reasoning paths.
"""
state = InputField(desc="Final state after failed attempt")
trace = InputField(desc="Full reasoning path")
goal = InputField(desc="Original goal text")
rationale = OutputField(desc="Why the attempt failed")
improvement_plan = OutputField(desc="Concrete steps to improve")
| Feature | Why It’s Important |
|---|---|
| ✅ Triggered when a trace scores poorly | Enables error-aware feedback |
✅ Inputs: state, trace, goal |
Full context for post-mortem |
✅ Outputs: rationale, improvement_plan |
Actionable self-diagnosis |
🪞 Why This Matters
- Debugging the Mind: Explains why a reasoning trace failed.
- Actionable Feedback: Suggests concrete steps critical for symbolic tuning and self-improvement.
- Mirror to Sharpening: Feeds into the sharpening loop when traces go wrong.
3. ValueEstimator: Trace Scoring
class ValueEstimator(Signature):
"""
Evaluates a reasoning path using a hybrid value function.
"""
state = InputField(desc="Current problem state")
trace = InputField(desc="Sequence of thoughts/actions")
goal = InputField(desc="Goal text")
score = OutputField(desc="Hybrid score (LM + self-consistency)")
rationale = OutputField(desc="Explanation of score")
🧠 ValueEstimator – Scoring Reasoning Paths
| Feature | Why It’s Important |
|---|---|
✅ Hybrid scoring via Predict(ValueEstimator) |
Combines LLM judgment + consistency checks |
| ✅ Structured inputs (state, trace, goal) | Enables trace-aware evaluation |
| ✅ Score normalization (0–1) | Allows comparison across steps or trees |
| ✅ Rationale output | Supports explainability and feedback loops |
This lets the system:
- Compare different reasoning paths fairly
- Justify choices with traceable rationales
- Provide signals for reflection and sharpening
📏 Why This Matters
- Multi-dimensional Scoring: Can plug into MR.Q, dimensional evaluators, or LM-based raters.
- Bridge Between Thought and Value: Ties reasoning directly to reward.
- Enables MCTS Guidance: Drives path selection in the tree search loop.
4. SharpeningPrompt: Prompt Refinement
class SharpeningPrompt(Signature):
"""
Sharpens hypotheses using dimensional feedback.
"""
hypothesis = InputField(desc="Original hypothesis")
feedback = InputField(desc="Dimensional scores and rationales")
goal = InputField(desc="Goal text")
refined_hypothesis = OutputField(desc="Improved hypothesis")
changes = OutputField(desc="Summary of changes made")
| Feature | Why It’s Important |
|---|---|
| ✅ Uses feedback + goal + hypothesis | Tuned rewriting of weak steps |
✅ Structured outputs: refined_hypothesis, changes |
Clear before/after diffs |
| ✅ Integrates with reflection and scoring | Completes the learning loop |
This allows the agent to:
- Rewrite bad steps using explicit feedback
- Learn from contrastive scoring
- Improve reasoning traces dynamically
✨ Why This Matters
- Dimensional Feedback Loop: Uses scores across dimensions (correctness, clarity, etc.) to generate a better hypothesis.
- Supports Iteration: Part of the feedback-and-fix mechanism within LATS.
- Link to Self-Training: Ties in directly with the broader Sharpening framework.
5. LATSProgram Module
At the heart of the DSPy-enhanced version of LATS is a structured reasoning module: LATSProgram. This component orchestrates the full decision-making loop, guiding the agent through:
- Reasoning via step-by-step generation (
TraceStep) - Scoring each path (
ValueEstimator) - Reflecting on weak traces (
ReflectionPrompt) - Refining suboptimal steps (
SharpeningPrompt)
class LATSProgram(dspy.Module):
def __init__(self, cfg, agent):
super().__init__()
self.cfg = cfg
self.agent = agent
self.generator = Predict(TraceStep)
self.value_estimator = Predict(ValueEstimator)
self.reflector = Predict(ReflectionPrompt)
self.sharpener = Predict(SharpeningPrompt)
self.max_depth = cfg.get("max_depth", 3)
def _estimate_value(self, state, trace):
"""Estimate value using LM-powered scorer"""
result = self.value_estimator(state=state, trace=trace, goal=state)
try:
score = float(result.score)
except:
score = 0.5
return score, result.rationale
def forward(self, state, trace, depth=0):
if depth >= self.max_depth:
return trace, self._estimate_value(state, trace)[0]
prediction = self.generator(state=state, trace=trace)
if not prediction or not prediction.next_step:
return trace, 0.0
next_step = prediction.next_step.strip()
new_state = self.agent._update_state(state, next_step)
new_trace = trace + [next_step]
child_trace, child_score = self.forward(new_state, new_trace, depth + 1)
if child_score < self.cfg.get("threshold", 0.7):
reflection = self.reflector(state=new_state, trace=child_trace, goal=state)
sharpened = self.sharpener(
hypothesis=next_step, feedback=reflection.rationale, goal=state
)
child_trace[-1] = sharpened.refined_hypothesis
new_state = self.agent._update_state(state, child_trace[-1])
score, _ = self._estimate_value(new_state, child_trace)
return child_trace, score
return child_trace, child_score
🔁 How It Works
The forward() method is the recursive engine that drives tree expansion. At each depth of the search:
- It generates the next step using the current
stateand reasoningtrace. - It updates the state based on the proposed step and recurses deeper.
- At each leaf (or depth limit), it scores the trace using a hybrid value estimator.
If a branch scores poorly (below threshold), the program doesn’t discard it it reflects on what went wrong, sharpens the step using feedback, and tries again.
This design embodies the LATS philosophy:
🪞 Don’t just fail fast fail reflectively and improve on the fly.
🧠 Why This Matters
The LATSProgram isn’t just a loop it’s a self-improving control system that captures what makes LATS different:
- Modularity: Each component (generation, scoring, reflection, sharpening) is swappable and trainable.
- Depth-Limited Search: Controlled tree traversal ensures bounded cost with maximum reasoning gain.
- Built-in Self-Critique: Every weak output is a chance to learn in real time.
You can think of this program as the neural backbone of LATS. Symbolic strategies, scoring modules, and pipelines wrap around it but this is where structured learning happens.
6. Integration in LATSAgent
class LATSAgent(ScoringMixin, BaseAgent):
def __init__(self, cfg, memory=None, logger=None):
self.lats_program = DSPyLATSProgram(cfg, self)
Why This Works
-
Separation of Concerns:
- LATS handles tree search
- DSPy handles prompt generation
- ScoringMixin handles evaluation
- ProximityAgent handles reuse
- RuleTuner handles symbolic evolution
-
Training Hook:
def _train_on_traces(self, traces): examples = [Example(state=trace["state"], trace=trace["trace"], next_step=trace["last_action"]) .with_inputs("state", "trace") for trace in traces] tuner = BootstrapFewShot(metric=self._dimension_aware_metric) self.program.generator = tuner.compile( student=Predict(TraceStep), trainset=examples )This lets you:
- Train on high scoring traces
- Improve future reasoning with few shot learning
- Evolve prompts using dimensional scores
📦 Full DSPy Integration Flow
graph TD
A[Goal: Which magazine was started first?]
B[TraceStep 1: Search for publication dates]
C[State 1: Goal + Step 1]
D[TraceStep 2: Compare search results]
E[State 2: Goal + Steps 1-2]
F[TraceStep 3: Determine final answer]
G[State 3: Goal + Full Trace]
A --> B
B --> C
C --> D
D --> E
E --> F
F --> G
subgraph DSPy [DSPy Program]
H[Signature: TraceStep]
I[Module: LATSProgram]
J[Training: BootstrapFewShot]
H --> I --> J
end
🧪 How It Works in Practice
Example Prompt Generation
state = "Improve the reasoning capabilities of an AI system by designing a feedback-driven learning loop."
trace = []
# Generate the next reasoning step
result = self.generator(state=state, trace=trace)
next_step = result.next_step
This might produce:
Thought 1: Introduce a mechanism to collect structured feedback on AI-generated outputs across multiple dimensions.
Observation: Feedback includes correctness, clarity, and insightfulness scores from evaluators.
Thought 2: Add a self-reflection module that analyzes incorrect outputs and identifies patterns in reasoning failures.
Observation: Reflection enables identifying failure modes like shallow reasoning or contradiction.
Thought 3: Implement a scoring system to rank outputs based on correctness, clarity, and insightfulness to guide improvements.
Observation: Scoring guides future learning by emphasizing strengths and revealing weaknesses.
Thought 4: Feed the feedback and scores into a prompt-tuning or rule-refinement module that updates future generations.
Observation: Improved prompts yield better reasoning quality in subsequent outputs.
Each step is generated by:
self.generator(state=state, trace="\n".join(trace))
Which is compiled from:
tuner = BootstrapFewShot(metric=self._dimension_aware_metric)
self.lats_program.generator = tuner.compile(
student=Predict(TraceStep),
trainset=weighted_examples
)
This illustrates how LATS reasons iteratively, building a trace of structured thoughts and how each step contributes to a self-improving reasoning process.
🧱 Signature Design Pattern
Why You’re Using It
-
Structured Input/Output:
state = InputField(desc="Current problem state") trace = InputField(desc="History of thoughts/actions") next_step = OutputField(desc="Next reasoning step") -
Separation of Reasoning and Action:
state: Full goal + historytrace: List of steps takennext_step: Structured action (thought/action)
This supports the LATS paper’s emphasis on:
- 🧠 Internal reasoning
- 🧮 External action
- 🔄 Iterative refinement
🎯 Training with Dimensional Guidance
Your training logic:
examples = [
Example(state=trace["state"], trace=trace["trace"], next_step=trace["last_action"])
for trace in high_scoring
]
Adds dimensional weights to guide learning:
def _dimension_aware_metric(self, example, pred):
scores = self._get_dimension_scores(pred.trace)
return sum(s["score"] * s.get("weight", 1.0) for s in scores.values()) / sum(...)
This means:
- ✅ Correctness weighted reasoning is prioritized
- ✅ Feasibility scores guide action generation
- ✅ Insightfulness drives hypothesis refinement
🧩 Real-World Use Case
Goal: “Will AI ever be able to reprogram itself?”
TraceStep Call
generator = Predict(TraceStep)
response = generator(state="Goal: Will AI ever be able to reprogram itself?", trace="")
Response
next_step: "Search for AI self-reprogramming research."
Recursive Reasoning
trace, steps = self.lats_program.forward(
state="Goal: Will AI ever be able to reprogram itself?",
trace=[]
)
Might generate:
[
("Goal: Will AI ever be able to reprogram itself?", "Search for AI self-reprogramming research.")
("Goal: Will AI ever be able to reprogram itself?\nThought 1: Search for AI self-reprogramming research.", "Evaluate self-consistency of AI systems during modification.")
("Goal: Will AI ever be able to reprogram itself?\nThought 1: Search for AI self-reprogramming research.\nThought 2: Evaluate self-consistency of AI systems during modification.", "Compare with human-guided code reviews.")
]
📌 Summary of DSPy Benefits
| Benefit | Implementation |
|---|---|
| ✅ Modular Prompting | TraceStep + ValueEstimator |
| ✅ Structured Reasoning | Uses state, trace, and next_step |
| ✅ Self-Improvement | Trains on high-quality traces |
| ✅ Multi-Stage Evaluation | Uses different signatures for reason/reflect/value |
| ✅ Training Feedback | Uses dimensional scores as weights |
🧩 Optional Enhancements
1. Dynamic Prompt Selection
def get_signature(goal_type):
if goal_type == "research":
return TraceStep
elif goal_type == "code":
return CodeStep
else:
return ThoughtStep
2. Self-Refinement with DSPy
def _refine_with_dspy(self, trace, feedback):
prompt = self.prompt_loader.load_prompt("sharpening", {
"trace": trace,
"feedback": feedback
})
# Use DSPy to refine the trace
refined = self.sharpener(prompt=prompt, trace=trace)
return refined.trace
3. Hybrid Scoring
def _estimate_value(self, state, trace):
result = self.value_estimator(state=state, trace=trace)
try:
score = float(result.score)
except:
score = 0.5
return score, result
📈 Key Takeaways
1. State Management Is Critical
- Use dictionary-based state from the start
- Never mix string and list traces
- Always store
goalseparately from evolving state
2. Structured Scoring Enables Evolution
- Rubric driven prompts produce interpretable scores
- Dimensional feedback guides reflection/refinement
- Score deltas drive symbolic rule mutation
3. Graph-Based Analysis Works
- Mermaid visualization helps debug tree search
- Impact analysis identifies divergent paths
- Proximity matching prevents redundant exploration
4. Self-Improvement Loop
graph LR
A[Goal] --> B[LATS Tree Search]
B --> C{Is Terminal?}
C -->|No| B
C -->|Yes| D[Score Evaluation]
D --> E[Reflection]
E --> F[Rule Mutation]
F --> G[MR.Q Training]
G --> H[New Goal]
This loop ensures:
✅ Failed paths generate reflections Sure
✅ Reflections guide rule tuning
✅ New rules improve future generations
Example Rule Mutation:
# Before
"Use simple words. Avoid technical terms unless necessary."
# After Reflection
"Add: When comparing dates, prioritize historical records over general web results."
📊 Performance Considerations
| Component | Best Practices |
|---|---|
| ✅ Tree Search | Keep max_depth ≤ 5 for stability |
| ✅ Scoring | Use 3+ dimensions for balanced evaluation |
| ✅ Reflection | Add to failed paths only |
| ✅ MR.Q Training | Use contrast pairs with ≥ 0.1 score difference |
| ✅ Mermaid Visualization | Limit to top 3 branches per node |
📌 Common Pitfalls & Fixes
1. String vs List Trace
Issue: node["trace"] was sometimes a string
Fix:
def resolve_node(self, node):
if isinstance(node, str):
return {"trace": node.split("\n")}
return node
2. Score Lookup Failures
Issue: EvaluationORM.score removed in schema update
Fix:
def _get_score(self, node, source="graph1"):
trace = node.get("trace", [])
if isinstance(trace, str):
trace = trace.split("\n")
score_result = self.score_hypothesis(
{"text": "\n".join(trace)},
{"goal": {"goal_text": node["state"].get("goal", "Unknown")},
metrics="lats_reflection"
)
return score_result["score"] / 100
3. Mermaid Graph Errors
Issue: node["trace"][-1] raised IndexError on root node
Fix:
# Safely extract last action
if not trace:
last_action = state.get("goal", "Root")
else:
last_action = trace[-1]
🧱 Code Structure
stephanie/
├── agents/
│ ├── base.py
│ ├── lats.py # LATS agent with tree search
│ ├── proximity.py # Similarity detection
│ ├── rule_tuner.py # Rule evolution
│ └── mrq.py # Reward modeling
├── analysis/
│ ├── score_evaluator.py
│ └── scorer.py
├── models/
│ ├── hypothesis.py
│ └── evaluation.py
└── utils/
└── graph_tools.py
🔍 Sample Prompt Engineering
Chain-of-Rubrics (CoR) Template
{% if mode == "reason" %}
Rubric:
- Does the hypothesis directly address the goal?
- Are all logical steps valid and free from contradictions?
<eval>
Evaluate the hypothesis:
Goal: {{ goal.goal_text }}
Hypothesis: {{ hypothesis.text }}
</eval>
<answer>[[85]]</answer>
{% endif %}
Reflection Template
Rubric:
- Does the reflection explain past failures?
- Is the improvement plan actionable?
<eval>
You attempted to solve:
{{ goal.goal_text }}
Your reasoning path:
{% for step in trace %}
- {{ step }}
{% endfor %}
Reflection:
</eval>
<answer>
{"rationale": "...", "improvement_plan": "..."}
</answer>
🧠 Lessons from the LATS Paper
From “LATS: Language Agent Tree Search”:
- Tree Search > Greedy Decoding: Explores multiple paths with UCT
- Reflection Improves Planning: Learn from failed trajectories
- Self-Consistency Matters: Combine LM score + self-consistency
- Environment Integration: Works with both reasoning and acting tasks
Our implementation extends this with:
- Symbolic Rule Tuning: Evolves prompt strategies based on feedback
- Graph-Based Analysis: Compares structural impact of different paths
- Dimensional Scoring: Scores across correctness, feasibility, insightfulness
📎 Integration Tips
1. Supervisor Pipeline
async def _run_pipeline_stages(self, context: dict) -> dict:
for stage in self.pipeline_stages:
agent = self._get_agent(stage)
context = await agent.run(context)
# Accumulate hypotheses in context
new_hypotheses = self.memory.hypotheses.get_all(
pipeline_run_id=context.get(PIPELINE_RUN_ID)
)
context["hypotheses"].extend([h.to_dict() for h in new_hypotheses])
return context
2. Proximity Matching
async def _refine_system(self, context):
high_scoring = [n for n in self.nodes if n.get("score", 0) > 0.8
if high_scoring:
await self.mrq_agent.run({"traces": high_scoring})
if context.get("graph_analysis"):
await self.rule_tuner.run(context)
3. Rule Mutation
def _tune_symbolic_rule(self, rule_name, context):
prompt = self.prompt_loader.load_prompt("rule_tuning", {
"rule": rule_name,
"feedback": context["reflection"],
"goal": context[GOAL]["goal_text"]
})
response = self.call_llm(prompt, {})
return self._parse_rule_update(response)
🧪 Example Workflow
-
Goal: “Which magazine was started first: Arthur’s Magazine or First for Women?”
-
Initial Prompt:
{ "state": "Goal: Which magazine was started first?", "trace": [], "mode": "reason" } -
First Completion:
"Thought 1: Search for publication dates" -
Reflection:
"The hypothesis lacks nuance and doesn't consider trade-offs between defense and autonomy." -
Rule Tuning:
"Add 'Use simple words. Avoid technical terms unless necessary.' to prompt"
🧬 Future Directions
1. Dynamic Prompt Selection
def get_prompt_template(goal_type):
if goal_type == "research":
return "research_prompt.j2"
elif goal_type == "code":
return "code_prompt.j2"
else:
return "default_prompt.j2"
2. Interactive Mermaid Dashboard
def visualize_search_tree(root):
mermaid_lines = build_mermaid_graph(root, max_depth=3)
return "\n".join(mermaid_lines)
3. Symbolic Rule Mutation
def _apply_rule_update(self, rule_name, rule_changes):
for node in self.nodes:
if rule_name in node.get("applied_rules", {}):
node["state"] = node["state"].replace(
rule_name, rule_changes["new_version"]
)
✅ Conclusion
Building self-improving AI systems requires:
- Tree-based search for exploration/exploitation balance
- Structured scoring for actionable feedback
- Symbolic rule evolution to refine strategies
- Graph analysis for divergence detection
- MR.Q training to automate improvements
By combining:
- LATS tree search
- Multi-dimensional scoring
- Symbolic rule tuning
- Mermaid visualization
We’ve created a system that:
- Learns from its own reasoning paths
- Refines strategies based on score deltas
- Visualizes its own decision-making
🧩 Next Steps for Developers
- Try It Out
Clone the co-ai repo and run:
python -m stephanie.main --config-name lats_dspy
💬 Final Thoughts
This system proves that:
LLMs can improve through structured feedback loops, not just scale
Unlike traditional approaches that treat LLMs as black boxes, we’ve built a transparent framework where:
- Every decision leaves a trace
- Every failure generates reflection
- Every score drives refinement
- Every path is analyzed for impact
We’re just scratching the surface. What if:
- The agent could self-modify its own code?
- The reward model predicted score deltas instead of absolute scores?
- The rule tuner rewrote prompt templates instead of just refining rules?
Let’s keep pushing the boundaries of structured reasoning, symbolic evolution, and self-improving systems.
Conclusion
We believe this marks a turning point in dynamic AI reasoning: a shift from static agents to self-aware problem solvers that adapt and evolve. By marrying symbolic structure with learning-based scoring, we inch closer to agents that can improve autonomously one reasoning step at a time.
Stay tuned for the follow-up post detailing how MR.Q and rule tuning drive real improvement across pipelines.
Sequence Diagram of process
sequenceDiagram
participant User
participant LATSAgent
participant NodeGenerator
participant LLM
participant Scorer
participant SymbolicTuner
User->>LATSAgent: Submit Goal
LATSAgent->>NodeGenerator: Create Root Node
loop Tree Search Loop
NodeGenerator->>LLM: Expand Node (generate next steps)
LLM-->>NodeGenerator: Return child nodes (actions, states)
NodeGenerator->>Scorer: Score each child (multi-dimensional)
Scorer-->>NodeGenerator: Return scores
alt Prune or Terminate
LATSAgent->>NodeGenerator: Select top nodes
else Expand further
LATSAgent->>NodeGenerator: Continue expanding tree
end
end
LATSAgent->>SymbolicTuner: Analyze high-impact traces
SymbolicTuner->>LATSAgent: Suggest or refine symbolic rules
LATSAgent-->>User: Return best answer + trace + rule impact
📚 References
-
Zhou, J., Shah, D., Grosse, R., & Leike, J. (2024). Language Agent Tree Search Unifies Reasoning, Acting, and Planning. arXiv:2310.04406 🔗 Link to paper
-
Silver, D., Huang, A., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484–489. 🔗 Link
-
OpenAI (2023). GPT-4 Technical Report. arXiv:2303.08774 🔗 Link
-
Hughes, E. (2025). Self-Improving Agents: Applying the Sharpening Framework to Local LLMs. [Blog + Codebase] 🔗 Blog post 🔗 Code
-
Hughes, E. (2025). The Self-Aware Pipeline: Empowering AI to Choose Its Own Path to the Goal. [Blog + Codebase] 🔗 Blog post 🔗 Code
-
Hughes, E. (2025). Programming Intelligence: Using Symbolic Rules to Steer and Evolve AI. [Blog + Codebase] 🔗 Blog post 🔗 Code
-
Hughes, E. (2025). Dimensions of Thought: A Smarter Way to Evaluate AI. [Blog + Codebase] 🔗 Blog post 🔗 Code
-
Hughes, E. (2025). MR.Q: A New Approach to Reinforcement Learning in Finance. [Blog + Codebase] 🔗 Blog post 🔗 Code
📘 Glossary
LATS (Language Agent Tree Search) An AI reasoning system that uses Monte Carlo Tree Search (MCTS) to simulate and evaluate multiple reasoning paths from a given goal. Combines structured search, dimensional scoring, and symbolic feedback.
MCTS (Monte Carlo Tree Search) A search algorithm that builds a tree of possibilities by simulating actions, scoring their results, and incrementally focusing on high-reward paths. Used here to explore different reasoning strategies.
Node
A state within the reasoning tree, containing the current reasoning step (state), a trace of past steps, and associated scores.
Trace The sequence of reasoning steps taken from the root to a node. Serves as a potential explanation or hypothesis.
Scoring Dimensions Qualities like Correctness, Clarity, Completeness, Feasibility, Insightfulness, and Alignment used to evaluate the reasoning quality of each trace.
CoR (Chain-of-Reasoning) Format A structured format for scoring outputs with detailed rationale per dimension. Originated from the Sharpening project and reused in LATS.
Sharpening A self-improvement framework where agents refine their outputs through structured feedback and contrastive preference modeling. Inspired parts of LATS’s scoring and symbolic analysis.
Proximity Agent An auxiliary agent that surfaces similar past reasoning traces or outputs based on embedding similarity, to guide reuse or comparison.
Symbolic Scoring Loop A feedback system that traces scoring patterns back to symbolic rules or strategy choices, allowing self-tuning of future reasoning behavior.
Dimensional Scoring A nuanced evaluation method that assigns scores along multiple axes (e.g., clarity, correctness) instead of a single pass/fail rating.
Rule Applier / Rule Refiner System components that inject or adapt symbolic reasoning rules in the prompt or execution strategy based on scoring outcomes.
Self-Aware Pipeline An architectural pattern where the AI not only performs tasks but reflects on its performance and adapts its strategy using structured evaluations.