Programming Intelligence: Using Symbolic Rules to Steer and Evolve AI

🧪 Summary
“What if AI systems could learn how to improve themselves not just at the level of weights or prompts, but at the level of strategy itself? In this post, we show how to build such a system, powered by symbolic rules and reflection.
The paper Symbolic Agents: Symbolic Learning Enables Self-Evolving Agents introduces a framework where symbolic rules guide, evaluate, and evolve agent behavior.
In this post, we’ll implement and extend these ideas using the CO-AI framework, enabling symbolic rules to steer agent configuration, prompt design, pipeline structure, and ultimately learn from their own impact.”
You’ll learn how to:
- Define symbolic rules with filters and attributes
- Apply them dynamically during pipeline execution
- Track their effects on agent outcomes
- Analyze, refine, and evolve them using LLM feedback and scoring
By the end, you’ll have a complete symbolic loop:
flowchart LR
A[Symbolic Rules] --> B[Execution]
B --> C[Scoring]
C --> D[Analysis & Optimization]
D --> E[New Rules]
E --> B
a self-tuning AI system.
❓ Why Bother?
Modern AI systems are notoriously hard to tune.
Every time an agent underperforms, developers are forced to manually tweak prompts, adjust models, or restructure the pipeline with no clear audit trail and limited reusability. Even worse, it’s often unclear why one configuration works better than another, and lessons from past tasks are rarely carried forward.
This blog post is about changing that.
We introduce symbolic rules declarative, interpretable policies that dynamically guide which agents, models, or strategies to use. Instead of hard-coding every decision, you write rules like:
if:
goal.type: theoretical
then:
model: mistral
adapter: cot_adapter
These rules are applied at runtime, evaluated after execution, and then refined based on performance, creating a feedback loop that learns how to learn.
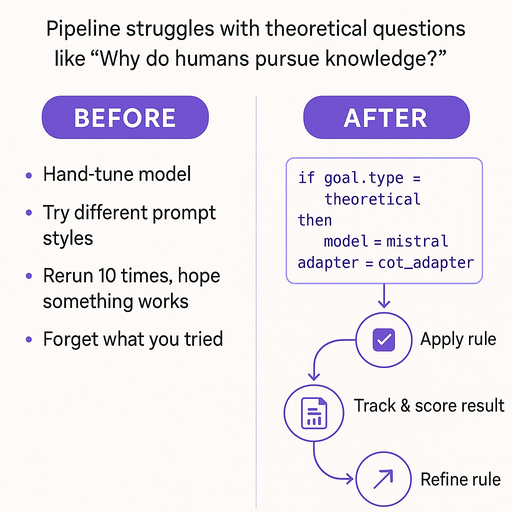
A Quick Before & After
Let’s say your pipeline struggles with theoretical questions like “Why do humans pursue knowledge?”
- Before: You hand-tune the model, try different prompt styles, rerun it 10 times, hope something works, then forget what you tried.
- After: You define a rule to route theoretical questions to a better reasoning agent using Chain-of-Thought and a specific model. The rule is applied, tracked, scored, and improved automatically over time.
No guesswork. No prompt spaghetti. Just clear symbolic guidance and a record of what worked, when, and why.
This symbolic feedback loop is modular, transparent, and adaptive transforming how we think about reasoning, tuning, and self-improving AI systems.
📜 The Symbolic Learning Paper
The core idea behind the symbolic learning paper is to bridge the gap between heuristic program design and machine learning. Rather than training neural models end-to-end, the authors suggest that agents can be driven by structured, human-readable rules. These symbolic rules:
- Apply at specific stages of reasoning or problem-solving,
- Modify the behavior of agents through declarative attributes (like prompt templates or model configs),
- Can be learned from data by analyzing their outcomes, and
- Support reflection, debugging, and interpretability unlike black-box models.
This turns the learning process into symbolic meta-optimization: instead of just optimizing weights, the system tunes its own strategy space.
🤖 Why Integrate This into Your Agent System?
Agent-based systems often involve:
- Custom pipelines,
- Model selection,
- Prompt tuning,
- Evaluation heuristics.
Symbolic rules provide a clean, declarative way to codify and tune these decisions. Integrating symbolic learning into Co AI (or your own agent framework) allows you to:
- Control and experiment with pipeline behavior using simple YAML files,
- Track which rules led to which outcomes,
- Analyze effectiveness across different tasks, and
- Evolve your system’s behavior without retraining models.
This closes the loop: rules → applications → outcomes → new rules, forming a self-improving symbolic reasoning system.
🧠 What You’ll Learn in This Guide
This post walks through the complete lifecycle of symbolic learning in practice:
-
Rule Design How to define rules declaratively with targets, filters, and attributes that apply to agents, prompts, goals, or entire pipelines.
-
Schema and Infrastructure How the Co AI database schema stores symbolic rules, rule applications, and scoring links.
-
Application Mechanism How rules are dynamically loaded and applied to agents during pipeline execution (via
SymbolicRuleApplier). -
Outcome Scoring How rule effectiveness is measured using structured LLM feedback or numerical metrics, stored with
ScoreORM. -
Analytics and Visualization How
RuleEffectAnalyzersurfaces insights like average score, success rate, and param performance. -
Learning and Refinement How
RuleRefinerAgentandRuleTunerAgentevolve rules over time based on performance. -
Future Directions
- Auto-generation of symbolic rules (
RuleGeneratorAgent) - Multi-agent voting on rule effectiveness
- Symbolic reward learning for reinforcement-style tuning
- Hybrid symbolic-neural meta-controllers
- Auto-generation of symbolic rules (
🧩 Mapping Paper Components to Practical Implementation
The symbolic learning paper introduces three core components: the Symbolic Pattern Learner, the Meta-Controller, and the Intervention Interface. Each of these plays a crucial role in enabling self-improvement via rule-driven reasoning. In this section, we’ll map these concepts to their real-world implementation in our agent-based Co AI system and explain the engineering choices that made this integration modular, traceable, and extendable.
🧠 1. Symbolic Pattern Learner → RuleRefinerAgent & RuleTunerAgent
Paper Description: Learns symbolic patterns (rules) from successful reasoning chains, extracting configurations that can be reused or generalized.
Our Implementation:
RuleRefinerAgent: Identifies underperforming rules based onresult_score, gathers statistics, and uses an LLM to propose refined rule edits or deprecation.RuleTunerAgent: Clones or mutates symbolic rules when they underperform compared to others in the same context, based ondelta_scoreacross rule applications.
Why this design:
- We separated heuristic mutation (Tuner) and LLM-based reflection (Refiner) to test both symbolic and learned evolution strategies.
- Each agent logs all changes and links them to outcomes using
RuleApplicationORM, allowing robust analysis of which learning method works better.
🧭 2. Meta-Controller → SymbolicRuleApplier
Paper Description: Applies learned symbolic rules to guide agent behavior in future runs, effectively acting as a control policy over reasoning stages.
Our Implementation:
SymbolicRuleApplierdynamically injects rule-based overrides into agent configs (apply_to_agent) or prompt logic (apply_to_prompt) during runtime.- Rules are selected based on
target,filter, andagent_namematching against goal metadata and context. - Applied rules are logged and linked to outcomes for later evaluation.
Why this design:
- Declarative rules in YAML are simple to author and easy to extend.
- Having a single
RuleAppliermodule allows unified enforcement of symbolic overrides across agent types, prompt formats, and pipeline stages. - Supports multi-agent pipelines by maintaining separation between rule logic and agent implementation.
🛠️ 3. Intervention Interface → Runtime Hooks in Agents
Paper Description: Provides a mechanism to dynamically intervene in the LLM reasoning process, modifying behavior on the fly.
Our Implementation:
-
Every agent’s
call_llmmethod checks for and applies symbolic rule overrides before executing the LLM call. -
These overrides can affect:
- Model selection (e.g.,
qwen,phi3) - Adapter modules (e.g.,
cot_adapter) - Prompt formatting (e.g., template name, temperature)
- Execution stages or control flags
- Model selection (e.g.,
-
PipelineJudgeAgentuses these overrides to trace which symbolic configurations led to which outcomes and scores.
Why this design:
- Agents remain stateless and configurable, making them composable and traceable.
- All interventions are logged via structured rules and linked to evaluations, enabling downstream optimization (e.g.,
RuleEffectAnalyzer).
🔁 Summary Table
| Paper Component | Our Implementation | Purpose |
|---|---|---|
| Symbolic Pattern Learner | RuleRefinerAgent, RuleTunerAgent |
Improve or mutate rules based on outcome-linked analytics |
| Meta-Controller | SymbolicRuleApplier |
Apply symbolic rules during agent execution |
| Intervention Interface | Agent hooks + call_llm() + rule injection |
Enable real-time control over model, prompt, and strategy |
🔧 System Overview: Co AI Framework
Before diving into the implementation details, let’s look at how symbolic learning fits into the broader CO-AI architecture a modular framework for dynamic reasoning pipelines, agent orchestration, and self-improvement.
flowchart TD
A[Goal Input + Evaluator] --> B[Pipeline Planner - Tree Search]
B --> C[Agent Nodes]
C --> D[Symbolic Rule Applier]
D --> E[Rule Store]
C --> F[Reflection / Scoring]
F --> D
F --> E
🔍 Components at a Glance
-
🎯 Goal Input + Evaluator A user-defined or system-suggested task (e.g., “generate a research hypothesis”). Evaluators define what success looks like scoring agents assess outputs based on accuracy, completeness, or other rubrics.
-
🧭 Pipeline Planner (Tree Search) Selects a sequence of agents or strategies to solve the goal think of it as dynamic task planning (e.g., generate → refine → score). Future versions can evolve this planner using symbolic learning feedback.
-
🧠 Agent Nodes Modular components like
ChainOfThoughtAgent,SharpeningAgent, orRetrieverAgentthat execute reasoning stages. Each agent is aware of symbolic rules and can be configured or altered based on them. -
🪄 Symbolic Rule Applier This is where symbolic learning shines. Rules are applied just-in-time to guide agent behavior, prompt structure, model choice, or pipeline composition. Example: “Use
mistralwithcot_adapterforreasoningtasks”. -
📦 Rule Store A structured database table (
symbolic_rules) that stores YAML-like rule entries, their context, source, and application history. This enables tracking, auditing, and learning over time. -
📊 Reflection & Scoring After agents produce hypotheses, scoring agents (like
LLMJudgeAgentorMRQSelfEvaluator) evaluate them. Scores are linked to rule applications and stored with context. This provides the feedback loop for learning.
🔁 Why Symbolic Learning Belongs Here
Symbolic learning integrates cleanly into this architecture because:
- It’s interpretable decisions can be logged, traced, and modified.
- It’s modular rules attach to specific agents, prompts, or goals.
- It’s learnable performance feedback lets the system evolve.
By embedding symbolic learning inside Co AI, we close the loop: → define a strategy → apply it → evaluate the results → improve the strategy → resulting in autonomously evolving agent behavior without retraining models.
🧵 How the Pipeline Ties Everything Together
In the Co AI framework, the pipeline is more than just a workflow it’s a symbolic execution trace that ties together goals, reasoning stages, symbolic rules, and results into a cohesive unit of learning.
At the center of this trace is the pipeline_run_id a unique identifier for every run that orchestrates all symbolic interactions.
🧩 The Role of pipeline_run_id
Every time a goal is submitted, it kicks off a pipeline run an isolated, traceable episode of reasoning. The pipeline_run_id binds together:
- ✅ The goal: what needs solving
- 🤖 The agents used to reason
- 📜 The symbolic rules that modified behavior
- ✍️ The prompts created and modified
- 💡 The hypotheses generated during reasoning
- 📈 The scores and feedback that measure success
- 🔁 The rule applications logged along the way
This means everything that changes every decision, output, evaluation, or symbolic intervention is permanently tied back to a single pipeline_run_id.
It’s a key design feature that enables:
- 🕵️♀️ Full auditability: You can reconstruct the exact conditions under which any result was produced.
- 🧠 Symbolic learning: Rule tuning agents use
pipeline_run_idto find patterns between rule application and outcome. - 📦 Modular memory: Hypotheses, prompts, scores, and logs are all grouped cleanly, making it easy to analyze performance by run, not just by rule.
🧠 Why This Matters
Symbolic optimization only works when outcomes can be traced back to causes. By attaching everything including hypotheses to the same pipeline_run_id, we create a closed feedback loop:
graph LR
A[Symbolic Rules] --> B[Pipeline Execution]
B --> C[Hypotheses + Scores]
C --> D[Analytics]
D --> E[Rule Refinement]
E --> A
Without this linkage, tuning rules based on performance would be guesswork. With it, we enable automated meta-optimization: the system learns which symbolic strategies work best under which conditions.
🗂️ What Gets Logged Under Each Run?
| Component | Linked by pipeline_run_id |
Example |
|---|---|---|
| Goal | ✔️ | goal_id = 42 |
| Agent Config | ✔️ | agent_name = cot_generator, model: mistral |
| Symbolic Rules | ✔️ | rule_id = 17, applied from source: manual |
| Prompt Template | ✔️ | prompt_id = 103, template: research_cot_template |
| Hypothesis | ✔️ | hypothesis_id = 88, reasoning: short CoT |
| Evaluation | ✔️ | score_id = 200, result: 7.8/10 |
| Rule Application | ✔️ | rule_id = 17 used in this run, impact: +1.2 score |
By using pipeline_run_id as the anchor, Co AI turns every reasoning run into a complete symbolic experiment ready for introspection, refinement, and learning.
🔧 Defining Symbolic Rules
Symbolic rules are interpretable YAML configurations stored in a rule database. Each rule targets one of:
prompt: modifies prompt constructionagent: adjusts model configs and parameterspipeline: restructures stagesgoal: sets global intent
Example:
- target: "agent"
agent_name: "generation_agent"
filter:
goal_type: "theoretical"
strategy: "reasoning"
attributes:
model: "mistral"
adapter: "cot_adapter"
Each rule includes:
target: where the rule applies (agent, prompt, etc.)filter: which goals it applies to (e.g. goal_type = research)attributes: what to changesourceanddescription(optional metadata)
🗂️ Schema and ORM Design for Symbolic Rules
Symbolic rules in our system are more than simple YAML snippets they’re persisted as full-fledged database records that support versioning, traceability, and analysis. This section outlines the design of the SymbolicRuleORM class and the underlying SQL schema.
🧱 The ORM: SymbolicRuleORM
Here’s the core structure of the symbolic rule object in SQLAlchemy:
class SymbolicRuleORM(Base):
# Main rule logic
agent_name = Column(String)
target = Column(String, nullable=False) # e.g. 'agent', 'prompt'
filter = Column(JSON) # matching logic
attributes = Column(JSON) # changes to apply
context_hash = Column(String, index=True) # hash for deduplication
goal_id = Column(Integer, ForeignKey("goals.id"))
pipeline_run_id = Column(Integer, ForeignKey("pipeline_runs.id"))
prompt_id = Column(Integer, ForeignKey("prompts.id"))
# Scoring and audit fields
rule_text = Column(Text)
score = Column(Float)
🔑 Design Highlights
| Feature | Why It Matters |
|---|---|
target, filter, attributes |
These are the core components that define how and where the rule is applied. |
context_hash |
Enables rule deduplication and clustering by logic rather than ID. |
goal_type, difficulty, etc. |
Enrich the rule with higher-level metadata for filtering and tuning. |
rule_text, score |
Provide semantic explanation and track performance over time. |
| Relationships | Enable reverse lookup from goals, prompts, and runs to rules for full traceability. |
🧮 Example SQL Table
For those working directly with Postgres or inspecting the schema, here’s the DDL for the symbolic_rules table:
CREATE TABLE IF NOT EXISTS public.symbolic_rules (
id SERIAL PRIMARY KEY,
target TEXT NOT NULL,
rule_text TEXT,
source TEXT,
attributes JSONB,
filter JSONB,
context_hash TEXT,
score DOUBLE PRECISION,
goal_id INTEGER REFERENCES public.goals(id) ON DELETE CASCADE,
pipeline_run_id INTEGER REFERENCES public.pipeline_runs(id) ON DELETE CASCADE,
prompt_id INTEGER REFERENCES public.prompts(id) ON DELETE CASCADE,
agent_name TEXT,
goal_type TEXT,
goal_category TEXT,
difficulty TEXT,
focus_area TEXT,
created_at TIMESTAMP DEFAULT now(),
updated_at TIMESTAMP DEFAULT now()
);
This hybrid design declarative YAML for authors, and structured ORM for execution and analytics lets us:
- Apply rules dynamically at runtime via agent hooks.
- Track outcomes and effectiveness with linked scoring.
- Compare rules contextually using
context_hash. - Optimize symbolic reasoning patterns using tools like
RuleRefinerAgentandRuleTunerAgent.
By treating symbolic rules as first-class citizens in the system, we create a closed loop of
flowchart LR
A[Declarative Guidance<br/>Symbolic Rules] --> B[Applied Execution<br/>Agents & Prompts]
B --> C[Performance Feedback<br/>Scores, Logs]
C --> D[Rule Improvement<br/>Refinement, Tuning]
D --> A
🧠 The Symbolic Rule Applier: How Rules Influence Execution
At the heart of symbolic learning in Co AI is the SymbolicRuleApplier. It’s the mechanism that dynamically injects symbolic intelligence into the pipeline, acting as a bridge between stored rules and live agent behavior.
💡 What It Does
The SymbolicRuleApplier takes declarative rules typically stored in the database or YAML and modifies pipeline behavior at runtime based on the current goal context. It’s responsible for:
- Selecting matching symbolic rules based on goal metadata
- Applying rule-driven overrides to agent configurations
- Modifying prompt parameters or templates
- Updating pipeline stage sequences
- Logging every application as a
RuleApplicationORM, tied topipeline_run_id
Think of it as the control layer that makes the pipeline strategy-aware and adaptable without hardcoding strategies into agents.
📦 When It Runs
The applier is invoked automatically during three moments in the pipeline:
-
Before agent instantiation:
apply_to_agent()injects configuration changes (like model, adapter, temperature). -
Before prompt generation:
apply_prompt_rules()updates the prompt config with symbolic-level tweaks (e.g. strategy hints, template overrides). -
During pipeline planning:
apply()can restructure the entire pipeline based on symbolicpipeline:directives.
At each step, the applier reads from memory, evaluates the rules, and modifies the configuration in-place.
🧪 How Matching Works
Each rule includes a filter section that specifies when it should activate e.g., for certain goal_type, difficulty, or agent_name.
filter:
goal_type: "research"
difficulty: "hard"
Matching is evaluated dynamically via _matches_filter() and _matches_metadata() methods. This ensures that only relevant rules are applied to the current goal.
📝 What It Logs
Every applied rule is recorded as a RuleApplicationORM, which includes:
rule_id: which symbolic rule was usedpipeline_run_id: the run where it was usedagent_name: where the rule was appliedstage_details: the resulting configurationcontext_hash: to track uniqueness and repetition
This turns every symbolic application into a data point for future evaluation and tuning.
{"timestamp": "2025-06-04T21:55:53.930992+00:00", "event_type": "SymbolicRulesFound", "data": {"count": 22}}
{"timestamp": "2025-06-04T21:56:02.690518+00:00", "event_type": "SymbolicAgentRulesFound",
"data": {"agent": "generation", "goal_id": 69, "count": 3}}
{"timestamp": "2025-06-04T21:56:02.690518+00:00", "event_type": "SymbolicAgentOverride",
"data": {"agent": "generation", "key": "name", "old_value":
"generation", "new_value": "generation", "rule_id": 2}}
{"timestamp": "2025-06-04T21:56:02.690518+00:00", "event_type": "SymbolicAgentOverride",
"data": {"agent": "generation", "key": "model",
"old_value":
{"name": "ollama_chat/qwen3", "api_base": "http://localhost:11434", "api_key": null},
"new_value":
{"name": "ollama_chat/phi3", "api_key": null, "api_base": "http://localhost:11434"}, "rule_id": 2}}
🔍 Why It Matters
Without the applier, symbolic rules are just inert config files. With it, Co AI gains:
✅ Declarative control over agents ✅ Auditable symbolic execution traces ✅ Pipeline-level adaptivity ✅ Data for scoring and learning
It also cleanly separates logic from execution, making it easy to debug, analyze, and evolve strategies without touching code.
🧠 Future Possibilities
The current implementation supports:
- Agent tuning
- Prompt customization
- Pipeline reshaping
In the future, you could extend this to:
- Trigger conditionals (e.g. if-score-falls → try new model)
- Learn activation conditions from past performance
- Combine symbolic rules with neural controllers
The SymbolicRuleApplier is the engine behind CO-AI’s self-tuning capabilities flexible enough to grow as your reasoning system evolves.
✨ Applying Rules at Runtime
Symbolic rules are not just static suggestions they are dynamically applied during pipeline execution. This enables real-time behavioral changes based on goal metadata, past performance, and current context.
🔁 Hooking Symbolic Rules into the Loop
During each pipeline run, we call the maybe_apply_symbolic_rules() method to modify agent configuration, prompt behavior, or even the entire pipeline structure:
def maybe_apply_symbolic_rules(self, context):
matching_rules = self.symbolic_rule_applier.find_matching_rules(context)
for rule in matching_rules:
if rule.target == "pipeline":
context["pipeline"] = self.symbolic_rule_applier.apply_to_pipeline(rule, context["pipeline"])
elif rule.target == "agent":
context["agent_config"].update(rule.attributes)
return context
This method leverages our SymbolicRuleApplier class, which supports applying rules to:
- Pipelines: change the sequence of agents based on task type.
- Agent Configs: override default parameters (e.g., switch models or adapters).
- Prompts: update template choices or formatting logic.
- Goal Metadata: inject strategy hints or tag difficulty.
Each rule includes:
filterto match context (e.g.,goal_type = research)attributesto apply (e.g.,model = qwen3,adapter = cot_adapter)targetwhat to modify (agent,pipeline,prompt)
This hook acts as a declarative controller, ensuring that logic isn’t hard-coded. Instead, the system reads rules at runtime, checks if they apply to the current context, and rewrites behavior accordingly.
⚙️ Declarative System Control
By placing this logic early in each pipeline execution, symbolic rules give us full declarative control over:
| Component | Rule Target | Example Rule Outcome |
|---|---|---|
| Pipeline | pipeline |
Replace default agent sequence for theoretical tasks |
| Agent Config | agent |
Override model to phi3 for complex reasoning |
| Prompt Format | prompt |
Swap in a CoT-based template for math-heavy goals |
| Evaluation | agent |
Switch to MR.Q-based judging if goal category = debate |
The runtime applier ensures that even if we deploy new agents or prompts, the rule system remains extensible and maintainable.
📌 Mapping Reasoning to Strategy
Instead of hard-coding logic for each use case, symbolic runtime application means:
- You can hot-swap strategies without code changes
- Every change is logged, scored, and attributed
- You can track rule performance and learn which interventions help
It’s programming with metadata, turning reasoning into a self-evolving symbolic loop.
📊 Measuring Rule Effectiveness
Symbolic rules aren’t just applied they’re tracked and scored to determine whether they improve AI reasoning quality.
Each time a rule is used, we log its application and impact using the rule_applications table:
CREATE TABLE IF NOT EXISTS rule_applications (
id SERIAL PRIMARY KEY,
rule_id INTEGER REFERENCES symbolic_rules(id),
pipeline_run_id INTEGER REFERENCES pipeline_runs(id),
pre_score FLOAT,
post_score FLOAT,
delta_score FLOAT,
applied_at TIMESTAMP DEFAULT NOW()
);
🔁 What Gets Tracked
Every symbolic intervention stores:
rule_id: the symbolic rule appliedpipeline_run_id: the unique run it was part ofpre_score: the model’s score before applying the rulepost_score: the outcome after applying the ruledelta_score: the performance change (positive or negative)applied_at: timestamp for auditing
This creates a complete performance trace for each rule application.
🧠 Learning from Outcomes
Once we’ve accumulated enough data, we can analyze which rules consistently improve performance. This is where our symbolic system starts to feel like reinforcement learning:
- If a rule improves delta score, it becomes preferred.
- If it performs poorly, we either tune or demote it.
This feedback loop is modeled similarly to DPO (Direct Preference Optimization) or MR.Q-style ranking but applied to symbolic metadata instead of raw tokens.
📈 Example Analytics
We use the RuleEffectAnalyzer to compute:
- Average delta per rule
- Win rate across tasks
- Score comparisons within context groupings (e.g., goal type or strategy)
These analytics inform:
- RuleTunerAgent: which rules to clone or tweak
- RuleRefinerAgent: which filters or attributes to optimize
- RuleGeneratorAgent: which symbolic patterns to synthesize from scratch
🔄 Closing the Loop
By continuously scoring rules in structured ways, the symbolic system becomes self-tuning:
graph LR
A[Rule Applied] --> B[Hypothesis Scored]
B --> C[Delta Computed]
C --> D[Performance Logged]
D --> E[Rule Updated or Replaced]
The result: a system that doesn’t just run logic it learns which logic to run.
🧮 Scoring Hypotheses: Ranking, Reflection, and Beyond
To evolve symbolic rules, we need structured, consistent evaluations of the outputs they influence. In Co AI, this is handled through a modular scoring system, where each hypothesis or output is evaluated across several dimensions:
🏅 1. Ranking (Pairwise Preference)
We use LLM-based judgment or MR.Q scoring to rank pairs of hypotheses:
- Which output is more helpful?
- Which follows better reasoning steps?
- Which aligns more closely with the goal?
These comparisons are recorded in a scores table and linked to their generating rules, allowing us to promote rules that lead to better outcomes.
CREATE TABLE IF NOT EXISTS scores (
id SERIAL PRIMARY KEY,
hypothesis_id INTEGER REFERENCES hypotheses(id),
symbolic_rule_id INTEGER REFERENCES symbolic_rules(id),
score_type TEXT, -- e.g., 'ranking', 'reflection', 'proximity'
value FLOAT,
rationale TEXT,
created_at TIMESTAMP DEFAULT NOW()
);
🪞 2. Reflection
Inspired by techniques like ReAct and Devil’s Advocate reasoning, we use self-critique scoring:
- Did the output follow a logical chain of thought?
- Were there hallucinations or unsupported claims?
- Could it be improved?
This is handled by a ReflectionAgent or JudgeAgent, which provides rationale and scores for interpretability.
📍 3. Proximity
The Proximity score measures how semantically close a hypothesis is to:
- The original goal
- A set of trusted ground-truths
- Or other high-scoring hypotheses
This acts like an embedding-based semantic plausibility metric, helping us surface hypotheses that are on-topic even if not perfect.
🧠 4. Meta Analysis
Finally, we apply meta-level judgments across all hypotheses in a run:
- Which strategy performed best?
- Did certain agents or prompts consistently outperform?
- Were symbolic rules actually helpful?
This is used to update symbolic rules in bulk (e.g., clone or remove underperforming ones), or even trigger new rule generation.
| Score Type | Agent / Source | Description |
|---|---|---|
pipeline_judgment |
PipelineJudgeAgent |
Reflective score evaluating the final hypothesis in context of the full pipeline. |
ranking |
LLMJudgeAgent or MR.Q |
Pairwise or absolute ranking of hypotheses for preference or quality. |
reflection |
LookaheadAgent / MR.Q |
Evaluation of planning or anticipation quality before execution. |
proximity |
ProximityAgent |
Measures how close a hypothesis is to a reference or gold standard. |
meta_analysis |
MetaAnalysisAgent |
Cross-comparison of multiple hypotheses using meta-level criteria. |
rubric_score |
MR.Q / Custom Evaluators | Score based on adherence to a rubric (clarity, correctness, novelty, etc). |
automatic_metrics |
Eval tools (e.g., BLEU, ROUGE) | Numeric score based on automatic similarity or generation metrics. |
user_feedback |
(Future / Optional) | Manual or implicit feedback from end-users. |
🧩 Adding Extra Scoring Dimensions
To move beyond a single scalar score, our system supports multidimensional evaluations of each hypothesis. This allows us to break down performance into interpretable components that can guide both symbolic rules and future learning algorithms.
🎯 Rubric-Based Scoring
When using agents like the LLMJudgeAgent, HypothesisScorerAgent, or MR.Q, we often return structured outputs that include specific dimensions such as:
overall: General effectiveness or plausibility of the hypothesis.relevance: How well the response aligns with the goal or input.clarity: Whether the explanation is easy to understand and logically coherent.originality: Degree of creativity or insight in the hypothesis.correctness: Accuracy based on the known facts or expectations.
These dimensions are logged and stored via the ScoreORM structure, and are available for analysis or rule evaluation. Each individual field acts as a feature for rule effectiveness, helping us pinpoint which strategies yield clarity vs. correctness vs. novelty.
🔍 Reflection Adds Meta-Level Dimensions
When using the ReflectionAgent or other anticipatory planning agents, we capture additional self-evaluation signals before generation. These include:
self_reward: The agent’s confidence in its own strategy.reward: The estimated usefulness of the upcoming hypothesis.feasibility: Whether the plan appears actionable and grounded.novelty: Expected novelty of the plan or hypothesis.correctness: Anticipated correctness based on internal simulation.
These fields are added to the reflection context and linked to the same pipeline_run_id, creating a full trace from reflection → generation → score. Over time, this trace can be mined by the RuleEffectAnalyzer to determine, for example, whether high self-reward correlates with actual downstream performance.
By capturing these rich dimensions:
- Rules can evolve to target specific objectives (e.g., boost clarity).
- The system can learn personalized strategies based on goal type or user preference.
- Agents can be optimized not just for accuracy, but for communication quality, creativity, or feasibility.
This sets the stage for truly self-aware symbolic optimization where the AI not only improves its answers, but understands which aspects of quality it’s improving.
An example reflection result
# Full Reflection Summary
The hypothesis is plausible and aligns with emerging evidence in biomedical AI, but lacks specificity and contextual depth to fully justify its broad claim.
# Strengths
- **Support from existing applications**: Generative AI has demonstrated success in drug discovery and biomolecular modeling, providing empirical backing.
- **Alignment with current trends**: Matches growing interest in AI-driven biomedical innovation and time-sensitive research challenges.
# Weaknesses
- **Overly broad scope**: Fails to specify which research tasks (e.g., drug discovery, target identification) or AI methodologies (e.g., diffusion models, reinforcement learning) are being referenced.
- **Assumes universal applicability**: Does not address potential limitations (e.g., data quality, domain-specific challenges) that could hinder time reduction in certain contexts.
# Correctness Assessment
Score: 4
Reasoning: Partially supported by existing case studies but lacks comprehensive empirical validation across all biomedical discovery domains.
# Novelty Assessment
Score: 3
Reasoning: Builds on established AI applications in biomedicine but offers a derivative claim rather than introducing novel methodologies or frameworks.
# Feasibility Assessment
Score: 5
Reasoning: Can be tested through targeted experiments in specific biomedical subfields, leveraging existing AI tools and benchmark datasets.
# Self-Reward Score
Score 75
# Recommended Refinements
- **Narrow the scope**: Specify target tasks (e.g., "drug candidate generation") and AI types (e.g., "diffusion models for molecular design").
- **Include contextual qualifiers**: Acknowledge limitations like data dependency or integration challenges with wet-lab workflows.
🔁 All Scores Tie Back to Symbolic Rules
Every score is linked to:
- A hypothesis
- The symbolic rule(s) applied during its generation
- The
pipeline_run_idthat ties the run together
This full audit trail powers the symbolic learning loop, giving us transparent, modular feedback for symbolic strategy optimization.
graph TD
Goal[🎯 Goal]
PipelineRun[🔁 Pipeline Run pipeline_run_id]
Hypothesis[💡 Hypothesis]
RuleApp[📜 Symbolic Rule Application]
Rule[📘 Symbolic Rule]
Score[📊 Score]
Goal --> PipelineRun
PipelineRun --> Hypothesis
Hypothesis --> Score
PipelineRun --> RuleApp
RuleApp --> Rule
RuleApp --> Hypothesis
Score --> RuleApp
subgraph "Symbolic Feedback Loop"
Rule -->|Guides| Hypothesis
Score -->|Informs| Rule
end
📊 Analyzing Rule Performance - RuleEffectAnalyzer
Once symbolic rules are applied and outputs are scored, the next step is to analyze their effectiveness. We use a dedicated utility called the RuleEffectAnalyzer to perform this analysis.
🧮 What It Computes
When symbolic rules are applied (via SymbolicRuleApplier), each application is recorded with:
- The rule ID used,
- The pipeline run ID,
- The agent and config details at the time,
- And eventually, a score from the evaluator.
The RuleEffectAnalyzer ties all this together and computes:
- ✅ Average score of each rule,
- 📉 Min / Max / Std Dev of score distribution,
- 🎯 Success Rate: Percent of scores above a certain threshold (e.g. ≥50),
- 🔧 Breakdowns by config: e.g. specific model + template combos.
class RuleEffectAnalyzer:
def _compute_stats(self, scores: list[float]) -> dict:
if not scores:
return {}
avg = sum(scores) / len(scores)
min_score = min(scores)
max_score = max(scores)
std = math.sqrt(sum((x - avg) ** 2 for x in scores) / len(scores))
success_rate = len([s for s in scores if s >= 50]) / len(scores)
return {
"avg_score": avg,
"count": len(scores),
"min": min_score,
"max": max_score,
"std": std,
"success_rate": success_rate,
}
def analyze(self, pipeline_run_id: int) -> dict:
"""
Analyze rule effectiveness by collecting all scores linked to rule applications.
Returns:
dict: rule_id → summary of performance metrics, broken down by param config.
"""
rule_scores = defaultdict(list)
param_scores = defaultdict(lambda: defaultdict(list)) # rule_id → param_json → scores
links = self.session.query(ScoreRuleLinkORM).filter(ScoreORM.pipeline_run_id == pipeline_run_id)
for link in links:
score = self.session.get(ScoreORM, link.score_id)
rule_app = self.session.get(RuleApplicationORM, link.rule_application_id)
if not score or not rule_app or score.score is None:
if self.logger:
self.logger.log("SkipScoreLink", {
"reason": "missing score or rule_app or score is None",
"score_id": getattr(link, "score_id", None),
"rule_application_id": getattr(link, "rule_application_id", None),
})
continue
rule_id = rule_app.rule_id
rule_scores[rule_id].append(score.score)
# Normalize stage_details as sorted JSON
try:
param_key = json.dumps(rule_app.stage_details or {}, sort_keys=True)
except Exception as e:
param_key = "{}"
if self.logger:
self.logger.log("StageDetailsParseError", {
"error": str(e),
"raw_value": str(rule_app.stage_details),
})
param_scores[rule_id][param_key].append(score.score)
# Build summary output
results = {}
for rule_id, scores in rule_scores.items():
rule_summary = self._compute_stats(scores)
results[rule_id] = {
**rule_summary,
"by_params": {},
}
print(f"\n📘 Rule {rule_id} Summary:")
print(tabulate([
["Average Score", f"{rule_summary['avg_score']:.2f}"],
["Count", rule_summary["count"]],
["Min / Max", f"{rule_summary['min']} / {rule_summary['max']}"],
["Std Dev", f"{rule_summary['std']:.2f}"],
["Success Rate ≥50", f"{rule_summary['success_rate']:.2%}"],
], tablefmt="fancy_grid"))
for param_key, score_list in param_scores[rule_id].items():
param_summary = self._compute_stats(score_list)
results[rule_id]["by_params"][param_key] = param_summary
print(f"\n 🔧 Param Config: {param_key}")
print(tabulate([
["Average Score", f"{param_summary['avg_score']:.2f}"],
["Count", param_summary["count"]],
["Min / Max", f"{param_summary['min']} / {param_summary['max']}"],
["Std Dev", f"{param_summary['std']:.2f}"],
["Success Rate ≥50", f"{param_summary['success_rate']:.2%}"],
], tablefmt="rounded_outline"))
return results
def pipeline_run_scores(self, pipeline_run_id: Optional[int] = None, context: dict = None) -> None:
"""
Generate a summary log showing all scores for a specific pipeline run.
....
🧾 Example Output
When run, the analyzer prints structured summaries like:
📘 Rule 7 Summary:
╒════════════════════╤════════════╕
│ Average Score │ 6.14 │
│ Count │ 12 │
│ Min / Max │ 4 / 9 │
│ Std Dev │ 1.23 │
│ Success Rate ≥50 │ 75.00% │
╘════════════════════╧════════════╛
🔧 Param Config: {"model": "qwen3", "template": "cot_template"}
┌─────────────────────┬────────────┐
│ Average Score │ 6.90 │
│ Count │ 8 │
│ Min / Max │ 6 / 9 │
│ Std Dev │ 1.01 │
│ Success Rate ≥50 │ 87.50% │
└─────────────────────┴────────────┘
This helps you answer:
- Which symbolic rules are actually working?
- In which contexts or config combinations do they shine?
- Should we promote, tune, or retire this rule?
🔁 Pipeline-Level Scoring
The analyzer also supports inspection by pipeline run:
analyzer.pipeline_run_scores(pipeline_run_id=42)
This logs each score entry tied to a pipeline run, including:
- The agent and model used
- The evaluator and score type
- The symbolic rule (if any) that contributed
This gives a run-by-run audit trail, useful for debugging or training new rule selectors.
🔄 Learning from Rule Performance
The real power comes from self-improvement. Our system includes three agents:
✏️ RuleRefinerAgent
Uses an LLM to rewrite poorly performing rules:
class RuleRefinerAgent(BaseAgent):
def __init__(self, *args, min_applications=3, min_score_threshold=6.5, **kwargs):
super().__init__(*args, **kwargs)
self.min_applications = min_applications
self.min_score_threshold = min_score_threshold
async def run(self, context: dict) -> dict:
self.logger.log("RuleRefinerStart", {"run_id": context.get(PIPELINE_RUN_ID)})
rule_apps = self.memory.session.query(RuleApplicationORM).all()
grouped = self._group_by_rule(rule_apps)
for rule_id, applications in grouped.items():
if len(applications) < self.min_applications:
continue
scores = [app.result_score for app in applications if app.result_score is not None]
if not scores:
continue
avg_score = statistics.mean(scores)
if avg_score >= self.min_score_threshold:
continue # Only refine low-performing rules
rule = self.memory.session.query(SymbolicRuleORM).get(rule_id)
self.logger.log("LowPerformingRuleFound", {
"rule_id": rule_id,
"applications": len(scores),
"avg_score": avg_score
})
refinement_prompt = self._build_prompt(rule, scores, applications)
response = self.call_llm(refinement_prompt, context)
self.logger.log("RefinementSuggestion", {
"rule_id": rule_id,
"suggestion": response.strip()
})
self.logger.log("RuleRefinerEnd", {"run_id": context.get(PIPELINE_RUN_ID)})
return context
def _group_by_rule(self, rule_apps):
grouped = {}
for app in rule_apps:
grouped.setdefault(app.rule_id, []).append(app)
return grouped
def _build_prompt(self, rule: SymbolicRuleORM, scores: list, applications: list) -> str:
attributes_str = str(rule.attributes) if rule.attributes else "{}"
filter_str = str(rule.filter) if rule.filter else "{}"
return f"""You are a symbolic rule optimizer.
The following rule has been applied {len(applications)} times with an average score of {statistics.mean(scores):.2f}.
Filter: {filter_str}
Attributes: {attributes_str}
Here are some example scores: {scores[:5]}
Please suggest improvements to this rule (e.g., modify attributes, adjust filter constraints, or recommend deprecation if not useful). Return only the proposed change."""
🧬 RuleTunerAgent
Uses statistical cloning to mutate underperforming rules:
- Monitoring the performance of existing symbolic rules.
- Identifying underperforming rules by comparing them to similar ones.
- Automatically generating improved variants (clones) of those rules with small modifications.
This agent implements a self-optimizing mechanism that helps the system adapt over time, ensuring only the most effective reasoning strategies are retained and reused.
class RuleTunerAgent(BaseAgent):
def __init__(self, cfg, memory=None, logger=None):
super().__init__(cfg, memory, logger)
self.min_applications = cfg.get("min_applications", 2)
self.min_score_delta = cfg.get("min_score_delta", 0.15)
self.enable_rule_cloning = cfg.get("enable_rule_cloning", True)
async def run(self, context: dict) -> dict:
# Step 1: Retrieve all symbolic rules
rules = self.memory.symbolic_rules.get_all()
suggestions = []
for rule in rules:
applications = self.memory.rule_effects.get_by_rule(rule.id)
self.logger.log(
"RuleApplicationCount",
{
"rule_id": rule.id,
"count": len(applications),
},
)
if len(applications) < self.min_applications:
continue
scores = [a.delta_score for a in applications if a.delta_score is not None]
if not len(scores):
continue
avg_score = sum(scores) / len(scores)
# Step 2: Compare with others in the same group
comparison_set = self.memory.rule_effects.get_by_context_hash(rule.context_hash)
baseline_scores = [a.delta_score for a in comparison_set if a.rule_id != rule.id and a.delta_score is not None]
if len(baseline_scores) < self.min_applications:
continue
baseline_avg = sum(baseline_scores) / len(baseline_scores)
delta = avg_score - baseline_avg
self.logger.log("RulePerformanceComparison", {
"rule_id": rule.id,
"avg_score": avg_score,
"baseline": baseline_avg,
"delta": delta,
})
# Step 3: If rule underperforms, clone with tweaks
if self.enable_rule_cloning and delta < -self.min_score_delta:
new_rule = self.mutate_rule(rule)
self.memory.symbolic_rules.insert(new_rule)
suggestions.append(new_rule.to_dict())
self.logger.log("RuleClonedDueToPoorPerformance", new_rule.to_dict())
context["rule_suggestions"] = suggestions
return context
def mutate_rule(self, rule: SymbolicRuleORM) -> SymbolicRuleORM:
new_attrs = dict(rule.attributes)
# Example tweak: toggle model if present
if "model.name" in new_attrs:
old_model = new_attrs["model.name"]
new_model = "ollama/phi3" if "qwen" in old_model else "ollama/qwen3"
new_attrs["model.name"] = new_model
return SymbolicRuleORM(
source="rule_tuner",
target=rule.target,
filter=rule.filter,
attributes=new_attrs,
context_hash=SymbolicRuleORM.compute_context_hash(rule.filter, new_attrs),
agent_name=rule.agent_name,
goal_type=rule.goal_type,
goal_category=rule.goal_category,
difficulty=rule.difficulty,
)
| Functionality | Description |
|---|---|
| Performance Monitoring | Tracks effectiveness using delta_score. |
| Statistical Comparison | Compares rules in the same context group. |
| Self-Improvement | Automatically evolves rule sets without human intervention. |
| Exploration Strategy | Introduces diversity by cloning with small mutations. |
🧩 Example Scenario
Imagine you have two rules for handling research-type goals:
- Rule A: Uses
qwen3→ average score = 7.0 - Rule B: Uses
phi3→ average score = 8.5
If Rule A consistently underperforms by more than min_score_delta, the RuleTunerAgent will generate a new version of Rule A that switches to phi3.
Over time, this leads to:
- More effective reasoning chains.
- Reduced reliance on suboptimal configurations.
- Continuous adaptation to task complexity and domain shifts.
What it does
- Monitors symbolic rule performance.
- Identifies underperforming rules by comparing them statistically.
- Automatically generates mutated variants to explore better strategies.
Why
- Enables continuous improvement without manual intervention.
- Adds exploration to the rule space, preventing stagnation.
- Closes the symbolic learning loop by acting on evaluation feedback.
🧪 RuleGeneratorAgent
The RuleGeneratorAgent is an autonomous component that:
- Analyzes high*performing pipeline runs.
- Groups them by common configuration patterns (e.g., model, agent, goal type).
- Identifies repeated patterns across multiple successful runs.
- Suggests new symbolic rules to apply those patterns automatically in the future.
class RuleGeneratorAgent(BaseAgent):
def __init__(self, *args, min_score_threshold=7.5, min_repeat_count=2, **kwargs):
super().__init__(*args, **kwargs)
self.min_score_threshold = min_score_threshold
self.min_repeat_count = min_repeat_count
async def run(self, context: dict) -> dict:
self.logger.log("RuleGeneratorStart", {"run_id": context.get(PIPELINE_RUN_ID)})
new_rules = []
# Step 1: Get high-scoring runs without rule applications
high_scores = self._get_high_performance_runs()
grouped = self._group_by_context_signature(high_scores)
for sig, entries in grouped.items():
if len(entries) < self.min_repeat_count:
continue
# Check if a rule already exists for this context
if self.memory.symbolic_rules.exists_by_signature(sig):
continue
# Step 2a: Heuristic-based rule suggestion
rule = self._create_rule_from_signature(sig)
if rule:
self.memory.symbolic_rules.insert(rule)
self.logger.log("HeuristicRuleGenerated", rule.to_dict())
new_rules.append(rule.to_dict())
else:
# Step 2b: LLM fallback
prompt = self._build_llm_prompt(entries)
response = self.call_llm(prompt, context)
self.logger.log("LLMGeneratedRule", {"response": response})
# Optionally parse/validate this into a SymbolicRuleORM
context["generated_rules"] = new_rules
self.logger.log("RuleGeneratorEnd", {"generated_count": len(new_rules)})
return context
def _get_high_performance_runs(self):
scores = self.memory.session.query(ScoreORM).filter(ScoreORM.score >= self.min_score_threshold).all()
runs = []
for score in scores:
rule_app = (
self.memory.session.query(RuleApplicationORM)
.filter_by(hypothesis_id=score.hypothesis_id)
.first()
)
if rule_app:
continue # Skip if rule already applied
run = self.memory.session.get(PipelineRunORM, score.pipeline_run_id)
if run:
runs.append((score, run))
return runs
def _group_by_context_signature(self, scored_runs):
grouped = defaultdict(list)
for score, run in scored_runs:
sig = self._make_signature(run.config)
grouped[sig].append((score, run))
return grouped
def _make_signature(self, config: dict) -> str:
# Could hash or stringify parts of the config, e.g. model + agent + goal
model = config.get("model", {}).get("name")
agent = config.get("agent")
goal_type = config.get("goal", {}).get("goal_type")
return f"{model}::{agent}::{goal_type}"
def _create_rule_from_signature(self, sig: str) -> SymbolicRuleORM:
try:
model, agent, goal_type = sig.split("::")
return SymbolicRuleORM(
source="rule_generator",
target="agent",
filter={"goal_type": goal_type},
attributes={"model.name": model},
agent_name=agent,
context_hash=SymbolicRuleORM.compute_context_hash(
{"goal_type": goal_type}, {"model.name": model}
)
)
except Exception as e:
self.logger.log("SignatureParseError", {"sig": sig, "error": str(e)})
return None
def _build_llm_prompt(self, entries: list) -> str:
examples = "\n\n".join(
f"Goal: {e[1].config.get('goal', {}).get('goal_text')}\n"
f"Agent: {e[1].config.get('agent')}\n"
f"Model: {e[1].config.get('model', {}).get('name')}\n"
f"Score: {e[0].score}" for e in entries[:3]
)
return f"""You are a symbolic AI pipeline optimizer.
Given the following successful pipeline configurations with high scores, suggest a symbolic rule that could be applied to future similar tasks.
Examples:
{examples}
Return a YAML snippet that defines a rule with `target`, `filter`, and `attributes`.
"""
In essence, the RuleGeneratorAgent allows your system to:
- Learn from success: Instead of hardcoding strategies, it finds what worked well.
- Generalize patterns: Turns individual wins into reusable strategies.
- Improve over time: Automatically adapts to new challenges by updating its rule base.
This agent is the “learning” part of your symbolic learning system while the SymbolicRuleApplier applies learned rules, this agent discovers them.
What it does
- Finds successful patterns in past runs.
- Groups them by shared traits.
- Creates symbolic rules that generalize those patterns.
- Applies heuristic first logic, falling back to LLM generated suggestions.
Why
- Enables automated learning without human intervention.
- Builds a foundation for truly self-improving language agents.
- Brings structure and control to the chaotic world of LLM reasoning.
🤹️ How to Integrate Symbolic Learning
- Define Rules: Add YAML rules to your database using the
SymbolicRuleORMformat - Use RuleApplier: In your agents, call
apply_to_agent(cfg, context) - Track Applications: Insert into
RuleApplicationORMviaRuleEffectStore - Score Results: Use
PipelineJudgeAgentor another scorer - Analyze: Run
RuleEffectAnalyzer.analyze()for performance breakdowns - Tune: Use
RuleRefinerAgentorRuleTunerAgentto evolve poor performers
✨ Summary: Toward Self-Tuning Reasoning Pipelines
graph LR
A[🎯 Goal] --> B[🛠️ Pipeline]
B --> C[🤖 Agents]
C --> D[💡 Hypotheses]
D --> E[📊 Scores]
E --> F[📜 Symbolic Rules]
F --> G[🔁 Next Pipeline]
This symbolic system in Co AI makes your pipelines:
- Explainable: Every decision is rule-based and logged
- Tunable: Rules adapt over time using LLM and heuristics
- Scalable: New stages, agents, and goals auto-inherit symbolic behaviors
As this loop improves, symbolic rules become not just configuration… but code.
✅ Mapping to the Paper
This implementation closely follows the design of
Symbolic Agents: Symbolic Learning Enables Self-Evolving Agents
, covering all its core components while also extending them in several key ways.
📐 Paper-to-Code Mapping
| Paper Component | Description | Implemented In | Notes |
|---|---|---|---|
| Goals | Tasks to optimize | goal object, logged to DB |
Each run is tied to a goal definition |
| Pipelines | Agent sequences to solve tasks | Supervisor, SymbolicRuleApplier, pipeline in context |
Dynamically modified via rules |
| Symbolic Rules | Declarative, human-readable control logic | SymbolicRuleORM, YAML rules, apply_to_pipeline() |
Rules can target pipeline, agents, prompts |
| Rule Applications | Instances of rules being applied | RuleApplicationORM, pipeline_run_id, stage_details |
Every change is traceable |
| Hypothesis Generation | Pipeline output hypotheses | hypotheses, pipeline_run_id |
Stored and linked to goals, agents, and rules |
| Scoring & Feedback | LLM-based evaluation of quality | PipelineJudgeAgent, ScoreORM |
Supports multiple score types |
| Reflection Feedback | Rich self-analysis feedback | lookahead.reflection, parsed into metrics |
Adds depth: reward, feasibility, novelty, etc. |
| Rule Attribution | Trace score → hypothesis → rule | ScoreRuleLinkORM, RuleEffectAnalyzer |
Enables symbolic credit assignment |
| Rule Optimization | Learn which rules to promote/demote | RuleEffectAnalyzer, RuleTunerAgent (planned) |
Based on score outcomes and parameter conditions |
| Audit Trail | Full trace of every step via ID linking | pipeline_run_id, rule_id, hypothesis_id |
Enables complete retrospective analysis |
💡 Bonus Extensions
In addition to the paper’s core system, this implementation adds new functionality:
- Multi-Dimensional Scoring: Scores aren’t just a number dimensions like
clarity,originality, andcorrectnessare included. - Reflection-Aware Feedback: We leverage internal agent reflection to surface latent qualities like
self_rewardandnovelty. - Parameter-Aware Analytics: Rule performance is broken down by model/template combinations (
stage_details). - Fully Auditable Feedback Loop: Every hypothesis, score, and rule application links back to the same
pipeline_run_id.
📚 References
-
Reflective Agents and Symbolic Learning
- ReReST: Reflection-Reinforced Self-Training for Language Agents https://arxiv.org/abs/2403.02877
-
Rule-Based Optimization Techniques
- Meta-SPO: Learning to Choose System Prompts for LLMs https://arxiv.org/abs/2310.01405
- General-Reasoner: Verifier-Guided Strategy Optimization https://arxiv.org/abs/2402.17194
-
Programmatic Prompt Engineering
- GROWS: Growing Reasoning Trees from Scratch https://arxiv.org/abs/2312.06606
-
Preference-Based Fine-Tuning
- Direct Preference Optimization (DPO) https://arxiv.org/abs/2305.18290
- MR.Q: Simple Preference-Based Training for LLMs (Internal implementation in Co AI, inspired by DPO)
-
Datasets and Benchmarks
- Chain-of-Thought Hub https://github.com/ysymyth/Chain-of-Thought-Hub
- General-Reasoner Evaluation Set https://huggingface.co/datasets/microsoft/general-reasoner-eval
-
Related Tools and Code
- Co AI Framework (Open Source) https://github.com/ernanhughes/co-ai
- DSPy: Declarative Self-Improving Programs https://github.com/stanfordnlp/dspy
🧠 Glossary
Agent A modular component in Co AI that performs a specific function such as generation, evaluation, or planning. Agents can be dynamically configured and modified at runtime using symbolic rules.
Co AI An open-source, modular AI research framework that supports pipeline orchestration, symbolic reasoning, scoring, and dynamic prompt programming using local or remote LLMs.
Context A structured dictionary passed between agents in a pipeline that contains the goal, pipeline ID, prompts, hypotheses, scores, and other runtime state.
Declarative Control A programming approach where behavior is specified by describing what should be done (e.g., via rules or configs), rather than how to do it. Symbolic rules provide declarative control over agent behavior in Co AI.
Evaluator An agent or model that assigns a score or label to a hypothesis. Evaluators can include MR.Q, LLM-based judges, or proximity/ranking algorithms.
Hypothesis A generated solution or response to a given goal. Each hypothesis is tied to the goal, the model or strategy that generated it, and a pipeline run ID.
Pipeline
A sequence of agents applied to a goal. The pipeline controls the order of operations (e.g., planning → generation → ranking → reflection). Every execution is tied to a unique pipeline_run_id.
Pipeline Run ID A unique identifier that tracks everything associated with a single execution of a pipeline: goals, agents used, rules applied, hypotheses generated, and scores computed.
Prompt A text template (often with Jinja syntax) used to condition LLMs for specific tasks. Prompts can be dynamically modified using symbolic rules.
Rule Application An event in which a symbolic rule is applied to modify a pipeline, agent config, or prompt. Each application is stored in the database and can be analyzed for effectiveness.
RuleEffectAnalyzer A tool that analyzes the effectiveness of symbolic rules by comparing the scores of hypotheses where rules were applied. It supports metrics like average score, min/max, and success rate.
ScoreORM The database object that stores structured evaluations of hypotheses (e.g., numeric scores, rationale, evaluator metadata).
SymbolicRuleApplier The system that matches and applies symbolic rules to various components (pipelines, agents, prompts) based on goal metadata and execution context.
Symbolic Rules Human- or AI-written instructions that declaratively modify the behavior of Co AI agents. Each rule can target specific agents, goal types, or prompt parameters.
Stage Details A structured (JSON) snapshot of an agent’s configuration at the time a rule was applied. Used to group and analyze performance by strategy.
MR.Q A preference-based scoring and training method used to evaluate and refine AI behavior without backpropagation. Co AI uses it to rank outputs and train smaller models.
PipelineJudgeAgent An evaluation agent that judges the overall output of a pipeline (e.g., a hypothesis) using LLMs or structured scoring logic. It also updates rule effect data post-run.